『データ可視化学入門』をRで書く 3.1 分布の特徴をとらえる
3.1 分布の特徴をとらえる
この記事はR言語 Advent Calendar 2023 シリーズ2の9日目の記事です。
qiita.com
3.1.1 基本的な分布の特徴
##### 3.1.1 ##### library(tidyverse) library(patchwork) set.seed(0) # 乱数のシードを設定(再現性のため) my_plot <- function(data, title){ data |> ggplot(aes(x = val, fill = name)) + geom_histogram(position = "identity",alpha=0.5, color = "black") + labs(title = title) + theme( legend.position="none", axis.title.x=element_blank(), axis.title.y=element_blank() ) } # 中央傾向:平均値が0と10の二つの分布 # 平均0、標準偏差1の正規分布に従う乱数を1000個生成 # 平均5、標準偏差1の正規分布に従う乱数を1000個生成 p1 <- bind_rows( data.frame(val = rnorm(1000, mean = 0, sd = 1), name = "a"), data.frame(val = rnorm(1000, mean = 5, sd = 1), name = "b") ) |> my_plot("ピークの位置") # 分散:分散が大きい分布と小さい分布 # 平均5、標準偏差1の正規分布に従う乱数を1000個生成 # 平均5、標準偏差3の正規分布に従う乱数を1000個生成 p2 <- bind_rows( data.frame(val = rnorm(1000, mean = 5, sd = 1), name = "a"), data.frame(val = rnorm(1000, mean = 5, sd = 3), name = "b") ) |> my_plot("広がりの度合い") # 形状:正規分布、左寄せの分布 # 平均5、標準偏差1の正規分布に従う乱数を1000個生成 # 形状パラメータ2、尺度パラメータ2のガンマ分布に従う乱数を1000個生成 p3 <- bind_rows( data.frame(val = rnorm(1000, mean = 5, sd = 1) , name = "a"), data.frame(val = rgamma(1000, shape = 2, scale = 2) , name = "b") ) |> my_plot("分布の形状") # ピーク:ピーク一つとピーク二つの分布 # 平均5、標準偏差1の正規分布に従う乱数を1000個生成 # 平均3、標準偏差1の正規分布と平均7、標準偏差1の正規分布に従う乱数を500個ずつ生成 p4 <- bind_rows( data.frame(val = rnorm(1000, mean = 5, sd = 1) , name = "a"), data.frame(val = c(rnorm(500, mean = 3, sd = 1), rnorm(500, mean = 7, sd = 1)), name = "b") ) |> my_plot("ピークの数と位置") # 外れ値:ごく少量の大きい外れ値が含まれている分布と含まれていない分布 # 平均5、標準偏差1の正規分布に従う乱数を995個と平均50、標準偏差5の正規分布に従う乱数を5個生成 # 平均5、標準偏差1の正規分布に従う乱数を1000個生成 p5 <- bind_rows( data.frame(val = c(rnorm(995, mean = 5, sd = 1), rnorm(5, mean = 50, sd = 5)), name = "a"), data.frame(val = rnorm(1000, mean = 5, sd = 1), name = "b") ) |> my_plot("外れ値") # 外れ値:外れ値が多少ある分布とほぼない分布 # 平均5、標準偏差1の正規分布に従う乱数を1000個生成 # 平均5、標準偏差1の正規分布に従う乱数を975個と平均15、標準偏差1の正規分布に従う乱数を25個生成 p6 <- bind_rows( data.frame(val = rnorm(1000, mean = 5, sd = 1) , name = "a"), data.frame(val = c(rnorm(975, mean = 5, sd = 1), rnorm(25, mean = 15, sd = 1)), name = "b") ) |> my_plot("外れ値?") (p1 + p2 + p3) / (p4 + p5 + p6)

3.1.2 ヒストグラムの形状とビンの定義
##### 3.1.2 ##### library(tidyverse) library(patchwork) set.seed(0) # 乱数のシードを設定(再現性のため) data_df <- data.frame(data = rnorm(100, 0, 1)) # 観測結果をデータフレームに変換 my_plot2 <- function(data, title, binwidth = 0.4, boundary = 0){ data |> ggplot(aes(x=data)) + geom_histogram( aes(y = after_stat(density)), fill = "blue", binwidth = binwidth, boundary = boundary ) + stat_function(fun=dnorm, color="red", linewidth = 1, linetype=2, args=list(mean=0)) + labs(title = title) + theme( legend.position="none", axis.title.x=element_blank(), axis.title.y=element_blank(), aspect.ratio = 1 ) } p1 <- data_df |> my_plot2("ビン幅 = 0.8", binwidth =0.8) p2 <- data_df |> my_plot2("ビン幅 = 0.4", binwidth =0.4) p3 <- data_df |> my_plot2("ビン幅 = 0.08", binwidth =0.08) p4 <- data_df |> my_plot2("boundary = 0", boundary = 0) p5 <- data_df |> my_plot2("boundary = 0.1", boundary = 0.1) p6 <- data_df |> my_plot2("boundary = 0.2", binwidth =0.2) (p1 + p2 + p3) / (p4 + p5 + p6)

3.1.3 正規分布との比較
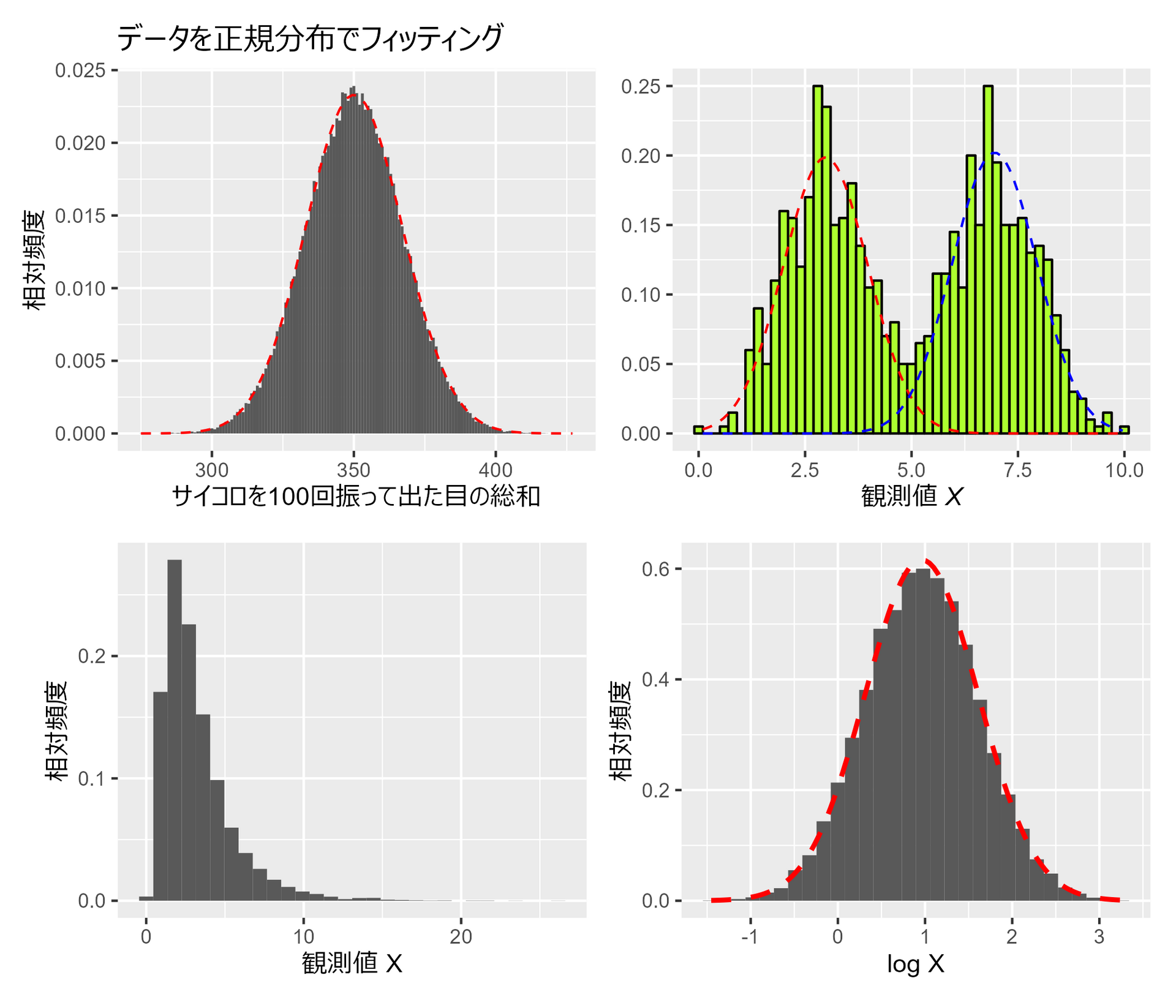
##### 3.1.3 ##### library(tidyverse) library(mclust) # 混合ガウシアンモデルのパッケージ library(MASS) library(patchwork) set.seed(0) # 乱数のシードを設定(再現性のため) # サイコロを100回振った時の出目の総和を10万回計算 # 元は1000回となっているがキレイな分布にならないので増やしてます roll_dice <- function(n = 100, repeat_num = 100000) { rowSums( matrix( sample.int(6, size = n*repeat_num, replace = TRUE), ncol = n ) ) } # ヒストグラムの作成 hist_data <- roll_dice() p1 <- data.frame(x = hist_data) |> ggplot(aes(x=x)) + geom_histogram(aes(y=after_stat(density)), binwidth=1) + stat_function(fun=dnorm, args=list(mean=mean(hist_data), sd=sd(hist_data)), color='red', linetype="dashed") + labs(title = "データを正規分布でフィッティング", x="サイコロを100回振って出た目の総和", y="相対頻度") + theme(aspect.ratio = 4/5) # 乱数のシードを設定(再現性のため) set.seed(0) # ピーク一つとピーク二つの分布 #平均3, 標準偏差1 と 平均7, 標準偏差1 の正規分布に従う乱数を500個ずつ生成 data4_b <- c( rnorm(500, mean = 3, sd = 1), rnorm(500, mean = 7, sd = 1) ) # 混合ガウシアンモデルのパラメータを推定 gmm <- Mclust(data4_b, G=2) # データと混合ガウシアンモデルの結果をプロット p2 <- data.frame(x = data4_b) |> ggplot(aes(x=x)) + geom_histogram(aes(y=after_stat(density)), binwidth=0.2, colour="black", fill="greenyellow") + stat_function( fun = function(x) gmm$parameters$pro[1] * dnorm(x, gmm$parameters$mean[1], sqrt(gmm$parameters$variance$sigma)), linetype = "dashed", color = "red" ) + stat_function( fun = function(x) gmm$parameters$pro[2]*dnorm(x, gmm$parameters$mean[2], sqrt(gmm$parameters$variance$sigma)), linetype = "dashed", color = "blue" ) + labs( titel = "データから2つの正規分布を推定", x = expression(paste("観測値 ", italic("X"))) ) + theme( aspect.ratio = 4/5, axis.title.y=element_blank() ) set.seed(0) # 乱数のシードを設定(再現性のため) # サンプルを生成 lognorm_samples <- rlnorm(10000, meanlog = 0.954, sdlog = 0.65) log_lognorm_samples <- log(lognorm_samples) # 対数変換 # 平均と標準偏差を推定 lognorm_fit <- fitdistr(log_lognorm_samples, densfun = "normal") p3 <- data.frame(x = lognorm_samples) |> ggplot(aes(x = x)) + geom_histogram(aes(y = after_stat(density))) + labs(x = "観測値 X", y = "相対頻度") + theme(aspect.ratio = 4/5) p4 <- data.frame(x = log_lognorm_samples) |> ggplot(aes(x = x)) + geom_histogram(aes(y = after_stat(density))) + labs(x = "log X", y = "相対頻度") + stat_function( fun=dnorm, color="red", size = 1, linetype=2, args=list(mean=lognorm_fit$estimate[1], sd=lognorm_fit$estimate[2]) ) + theme(aspect.ratio = 4/5) (p1 + p2) / (p3 + p4)
3.1.4 様々な理論分布
##### 3.1.4 ##### library(tidyverse) library(patchwork) # 描画用一時関数 my_plot_line <- function(df, color, title) { ggplot(df, aes(x = x, y = y)) + geom_line(color = color, linewidth = 2) + labs(title = title) + theme( axis.title.x=element_blank(), axis.title.y=element_blank() ) } my_plot_point <- function(df, color, title) { ggplot(df, aes(x = x, y = y)) + geom_point(color = color) + labs(title = title) + theme( axis.title.x=element_blank(), axis.title.y=element_blank() ) } # 一様分布 uni_p <- tibble( x = seq(-1, 1, length.out = 1000), y = dunif(x, min = -1, max = 1) ) |> my_plot_line("orange", "一様分布") # 正規分布 norm_p <- tibble( x = seq(-4, 4, length.out = 1000), y = dnorm(x) ) |> my_plot_line("red", "正規分布") # 二項分布 bin_p <- tibble( x = 0:10, y = dbinom(0:10, size=10, prob=0.5) ) |> my_plot_point("blue", "二項分布") # ポアソン分布 poi_p <- tibble( x = 0:9, y = dpois(0:9, lambda = 3) ) |> my_plot_point("forestgreen", "ポアソン分布") # 指数分布 exp_p <- tibble( x = seq(0, 10, length.out = 1000), y = dexp(x) ) |> my_plot_point("purple", "指数分布") # ガンマ分布 gam_p <- tibble( x = seq(0, 10, length.out = 1000), y = dgamma(x, 5) ) |> my_plot_point("brown", "ガンマ分布") # ワイブル分布 wei_p <- tibble( x = seq(0.01, 2, length.out = 1000), y = dweibull(x, 1.5) ) |> my_plot_point("grey", "ワイブル分布") # 対数正規分布 ln_p <- tibble( x = seq(0.01, 10, length.out = 1000), y = dlnorm(x) ) |> my_plot_line("pink", "対数正規分布") # パレート分布 paretofunc <- function(x, alpha = 5, xm = 1) alpha * (xm^alpha) / (x^(alpha+1)) pare_p <- tibble( x = seq(1, 4, length.out = 1000), y = paretofunc(x) ) |> my_plot_line("cyan", "パレート分布") # グラフを並べて表示 uni_p + norm_p + bin_p + poi_p + exp_p + gam_p + wei_p + ln_p + pare_p + plot_layout(ncol = 2)

3.1.5 累積分布でデータを視る
##### 3.1.5 ##### # 正規乱数を生成するためのシードを設定 library(tidyverse) set.seed(0) # 正規分布から100点と500点のサンプルを生成 samples <- rnorm(600) p1 <- tibble( x = samples[1:100], fill = if_else(x >= quantile(x, 0.8), "80%点以上", "80%点未満") ) |> ggplot(aes(x = x, fill = fill)) + geom_histogram() + labs(x = "観測値", y = "頻度") p2 <- tibble(x = samples[1:100]) |> ggplot(aes(x = x)) + stat_ecdf(pad = FALSE, color = "blue") + stat_function(fun=pnorm, color = "red", linetype = 2) + labs(title = "サンプルサイズ=100", x = "観測値", y = "累積相対頻度") p3 <- tibble(x = samples[101:500]) |> ggplot(aes(x = x)) + stat_ecdf(pad = FALSE, color = "blue") + stat_function(fun=pnorm, color = "red", linetype = 2) + labs(title = "サンプルサイズ=500", x = "観測値", y = "累積相対頻度") (p1 + plot_spacer()) / (p2 + p3)

第3章1節は以上です。