モダンチョキチョキズ 保山ひャンの朗読書き起こしと注釈(2024年12月15日心斎橋ビッグキャット)
2024年12月15日、心斎橋ビッグキャットにてモダンチョキチョキズのライブが開催されました。
今回のライブの前半では保山ひャンによる「ボンゲンガンバンガラビンゲンの伝説」の朗読が大きくフューチャーされています。
実はこの朗読には夥しい量の引用、オマージュ、パロディー、パスティシュが含まれており、知らなくても十分楽しめるのですが、そのコンテキストを知るとより楽しめる仕組みになっています。
ライブ後のインスタライブにて保山ひャンご本人から「文字起こししてください、だれか」というお話が出ました。12分30秒ぐらいから。
この文字起こしは南三条さんが早々にやられています。
#モダチョキアーカイブ観て好きなシーン
— 南三条 (@verteaile74) 2024年12月15日
保山ひャンの語り
(画像貼り慣れてないのでサイズ感はご容赦を) pic.twitter.com/vxeivrP7Zm
私の方では南三条さんの書き起こしをベースに、可能な限り注釈を加えました。
私が見落としているものがあったら教えてください。
これを読むと怪人保山ひャンの知識の深淵に少しだけ触れることができるかもしれません。
それではどうぞ!
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
あれから30年
そしてそれから1年
糅てて加えてそれから3ヶ月
そして30秒
はらたいら*1に300ペセタ*2
そして母を訪ねて3000ガバス*3*4
そして毎月3日は消費税3%の日*5
ボンゲンガンバンガラビンゲン
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
今は昔、曇天の空に輝く7つの星があった。
それはボン・ゲン・ガン・バン・ガラ・ビン・ゲンの7つ星である。
その七つ星は柄杓の形につながる北斗七星で、これぞ末世を救う(掬う)柄杓だと人々は期待を寄せたのである。
この北斗七星の航跡を追って星を追いかけたのは、星を追いかけることに関してはエキスパートの東方の三博士*6である。
東方の三博士は旅に出ました。
東方の三博士は、船を使った追跡は航海(後悔)につながると忌み嫌う。
東方だけに、徒歩にて追いかけた。
さて、末世とは何ぞや。
ブレートテクトニクス*7の大陸移動の衝突により、いわゆるトラフが生じ、地球に切り取り線が引かれたということは皆さんご存じですね。
ご存じでない?
この切り取り線が、太古の遺跡を直線状に並べた、いわゆるレイライン*8を断ち切ってしまい、封印を破ってしまったのです。
もしも切り取り線が開かれてしまえば、地底からマグマとアクマとカルマとヒグマと佐久間式ドロップスがドロップアウトしちゃうよ。
これが末世。
人類みんな往生しまっせ(末世)*9。
あ、ここギャグです。
困った人類はどうしたか。
困った時は皆さん、ご存じですね。
アメリカさんに頼めばいい。
そこで星を追った東方の三博士とは別に、世界を救うためにアメリカを目指したのがかのNGワードコロンブス*10だったのです。
しかし皆さん、考えてみてください。
大陸は常に移動するさまよえる湖*11。
ここかと思えばまたまたあちら*12。
復活不能と思われていたオアシス*13でさえも、復活してしまうこの異常気象。
案の定、NGワードコロンブスはかつてインドとアメリカを間違えた方向音痴ぶりの前科があるので、それをまた方向音痴を発揮してたどり着いたのがここ大阪ミナミだったのです。
NGワードコロンブスは、第1村人*14たちに聞きながら、「え?アメリカ?それはアメリカ村のことちゃうん。知らんで、アメリカ知らんで。アメリカ村やったら知ってるわ」
そのようなことを次々聞き、アメリカ村を探すことにしました。
え〜っと、アメリカ村ってどこにあるの。
アメリカ村ってどこにあるの。
アメリカ村ってどこにあるの。
ボンゲンガンバンガラビンゲン、ボンゲンガンバンガラビンゲン
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
赤、赤は赤血球*15
白、白は白血球
犬はワンケッキュウ
猫、猫はニャーケッキュウ
象、象はパオケッキュウ
蛇、蛇はニョロケッキュウ
ミッキー、ミッキーはチューケッキュウ
ドナルドはガーケッキュウ
中学の時の同級生西川君、西川君は、へえへえ、えへえへえ、えへえへ、保山なんかに聞かせるのはもったいないわーいケッキュウ
しょうざぶろう、ぼくの父親保山しょうざぶろう、保山しょうざぶろうは運動会、もういいかい、運動会、ああそうかい、運動会、もういいかい、もういいかい、もういいかい、いいのか! まだか、もういいにしてくれ息切れた。もういいかい。
ボンゲンガンバンガラビンゲン
ボンゲンガンバンガラビンゲン
はい!
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
「しとやかな獣」
その動物は全長50m、帝都を震撼させたゴジラの身長に匹敵し、尻尾の長さと髭の長さを加えるとゆうに20億光年の孤独*16をかこつ、宇宙規模の大きさを誇っている。
大きな猫ちゃん、ビッグキャット、大きなにゃんこ、ビッグキャット、アイロンのコード、ビッグキャット、愛ちゃんは店長メリメリーチョコレート*17、バキュン、 be my baby be my baby*18
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
その魚介類について説明しよう。
うお座をくわえたビッグキャットを追いかけて*19、阿弥陀如来を頭に埋め込んで高速で駆けていく女*20。裸足でアキレス腱は亀には追いつかない*21。
大きなつぼ焼き、ビッグサザエ、くわえていったのはビッグキャット。
アイアイアイアイアイランド、ビビビビビッグキャット*22。
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
ボンゲンガンバンガラビンゲン俳句大会
さあ、やってまいりました、何がや
ボンゲンガンバンガラビンゲン俳句大会、どこでや
ここ、心斎橋はビッグキャットにおいて、どないや
どないもこないもない、いつや
ただいまより、ただいま×ただいま×ただいま参上や
かわいいかわいい魚や*23
キリスト様が生まれた、馬小屋*24
聖徳太子が生まれた、も一回馬小屋パート2*25
僕の住んでるのはあばらや、ほっといてくれ
ほとけほっとけホットケーキ
というわけで楽しんでまいりましたボンゲンガンバンガラビンゲン俳句大会
次週のお話は、カツオ鉋で削られる、カツオ武士道を極める、カツオ勝負に負けるの3本でお送りします。
来週も見てね〜、ゴクン、カジャググ*26*27
ボンゲンガンバンガラビンゲン
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
NGワードコロンブスがアメリカ村にたどり着いたその時、向こうの方から何やら口ずさむ歌が聞こえてきた。
北斗とミナミ〜、北斗とミナミ〜*28、北斗七星を追いかけて旅をしていた東方の3%だ。
北斗七星の柄杓が救いの手を差し伸べていたのは、天の北斗を地表に投影した合わせ鏡の南斗だったのだ。ここ大阪ミナミは南の都、南斗だ。
南斗から発せられた勅令*29は、プロテスタントの信仰だけではなく、人類の存在を許すお墨付きとなるのだ。
北斗の七つ星、ボン・ゲン・ガン・バン・ガラ・ビン・ゲンはそれぞれドレミファソラシの七つの音階に当てはめられ、歌がとけて川になって流れてゆきます*30。
七つの星はつながって、メロディーとなり、地球の切り取り線上に張り付いて、治療するバンドエイドになりました。
人類よ癒されよ。
お前はもう神殿にいる*31。
ボンゲンガンバンガラビンゲンをおんぷちゃん*32に変えた歌は、石でできたピンポン台に、モーゼの十戒のごとく刻まれた。
NGワードコロンブスは、この石の卓球台*33に刻まれたその歌を、鉄のかけらに 移し替えて持ち帰った。
その鉄のかけらは未確認鋼鉄物体。
Unidentified Steel Object、略してUSOと呼ばれた。
我々モダンチョキチョキズは、この鉄のかけら、つまり天辺のUSOをたまたまこのビルの地下にあるサンキューマート*34で、2つ390円で入手した。
それを楽譜に再現したのがこれから演奏する曲です。
現代の末世的状況を救うためにこの歌を送ります。
天辺のUSO改め天辺の嘘。
天辺の嘘をお聞きください。
お前はもう神殿にいる。
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
こうして世界は七つ星の柄杓で救われた。
またいつか地球にキッキ*35が訪れた時は、七つ星はクリスマス限定のアイドルユニットとして再び現れるであろう。*36
しかしそれはまた別のお話。
真実はいつも3つ。*37
読み聞かせはお口の恋人*38保山ひャンでした。
メリークリスマスレディースアンドジェントルマンおとっつぁんお母さん*39、ありがとうございました。
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
以上です!
*1:日本の漫画家、随筆家、タレントでクイズ番組『クイズダービー』の名回答者として知られる。非常に正解率が高く「はらたいらさんに3000点」という慣用句が「確実性の高い選択にすべてをかける」といった意味で使われる。
*2:ペセタとは1998年12月31日まで発行されていたスペイン、およびアンドラの通貨単位。
*4:ガバスとはゲーム雑誌「ファミ通」誌上で使えるポイントサービス。
*5:保山ひャンの持ち歌「3%の歌」https://www.youtube.com/watch?v=f7VH7ypIFSI
*6:東方の三博士とは、新約聖書に登場し、イエスの誕生時にやってきてこれを拝んだとされる人物。メルキオール、バルタザール、カスパール。東方で見た星の導きに従い、幼子イエスを発見した。
*7:プレートテクトニクスは、1960年代後半以降に発展した地球科学の学説。地球の表面が、何枚かの固い岩盤(「プレート」と呼ぶ)で構成されており、このプレートが互いに動くことで大陸移動などが引き起こされると説明するもの。
*8:レイラインとは、古代の遺跡には直線的に並ぶよう建造されたものがあるという仮説で、その遺跡群が描く直線をさす。レイラインが提唱されているケースには古代イギリスの巨石遺跡群などがある。
*10:2024年6月にYouTube上で公開されたロックバンドMrs. GREEN APPLEの新曲「コロンブス」のMVが、歴史や文化的な背景への理解に欠ける表現が含まれていたために公開停止された件の引用。
*11:中央アジア、タリム盆地のタクラマカン砂漠北東部に、かつて存在した内陸湖ロプノールのこと。
*12:ピンク・レディー「渚のシンドバット」からの引用。ピンク・レディーには「UFO」という楽曲もある。
*13:メンバーの不仲のため再結成は不可能と思われていたイギリスのロックバンドOasisが再結成を発表した件の引用。
*14:日本テレビ系列で放送されているバラエティ番組『笑ってコラえて!』の企画「ダーツの旅」に出てくるお決まりのセリフ。最初に出会った住人。
*15:映画『戦場にかける橋』のテーマ曲「クワイ河マーチ」のメロディー。
*16:今年11月に他界した谷川俊太郎の詩集『二十億光年の孤独』からの引用
*17:保山ひャンが昔から仲良しの愛ちゃんがメリーチョコレートの店長だと言ってるだけの私的なギャグ
*18:COMPLEX「BE MY BABY」の引用。ほかにも引用されている楽曲がありそうだが不明。
*19:アニメ『サザエさん』の主題歌「サザエさん」の歌詞「お魚くわえたドラ猫 追っかけて」より
*20:モダンチョキチョキズ「有馬ポルカ」より
*23:童謡「かわいい魚屋さん」からの引用
*24:イエス・キリストが馬小屋で生まれたとされることからの引用
*26:TVアニメ『サザエさん』のエンディングからの引用。なお、このタイプのエンディングは1991年10月13日で放映終了。
*27:カジャグーグー(Kajagoogoo)は、ニューウェーブを代表するイギリスの音楽グループ。
*28:『ウルトラマンA』の主題歌「ウルトラマンエースの歌」からの引用。
*29:ナントの勅令。1598年、フランス国王アンリ4世がナントにて発布した勅令。プロテスタントの信仰の自由を認め、ユグノー戦争は終結に向かった。
*30:キャンディーズ「春一番」の歌詞「雪が溶けて川になって流れてゆきます。」より
*31:アニメ『北斗の拳』の決め台詞「お前はもう死んでいる」からの引用
*32:アニメ『おジャ魔女どれみ』シリーズの登場人物である魔女見習いの少女。声優は宍戸留美。魔法の呪文は「プルルンプルン ファミファミファ」。
*33:電気グルーヴのメンバー石野卓球からの引用。電気グルーヴはキューンソニー時代のレーベルメイト。
*34:全品390円(税込429円)の雑貨店
*36:1990年11月に結成されたクリスマス限定アイドルユニット「七つ星」からの引用。宍戸留美を含む7人組。
*37:『名探偵コナン』の主人公・江戸川コナンの決め台詞「真実はいつもひとつ」から
*38:ロッテグループのキャッチフレーズ「お口の恋人」から
for文を無くして高速化したいがfor文の方が速い
こちらのPythonのコードのデモデータ生成部分をR言語で再現したい。
https://github.com/tkEzaki/data_visualization/blob/main/8%E7%AB%A0/8_1_4_legend_examples.py
import pandas as pd # データフレーム操作のためのPandas import numpy as np # 数値計算のためのNumPy np.random.seed(0) # 乱数のシードを固定 # 月曜日から日曜日までの7日間 days_of_week = ['月', '火', '水', '木', '金', '土', '日'] # 各時刻 hours_of_day = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20] # データフレームを作成 df_visitor_count = pd.DataFrame(index=days_of_week, columns=hours_of_day) # パターンに基づいて来客数を生成する関数(水曜日の特別処理を含む) def generate_visitor_count_with_wednesday(day): visitor_count = [] for hour in hours_of_day: if day == '水': # 水曜日は12時と17時以外の時間に、普段の平日より1.5倍の来客 if hour == 12 or hour == 17: visitor_count.append(np.random.randint(50, 80)) else: visitor_count.append(int(np.random.randint(20, 50) * 1.4)) elif day in ['土', '日']: # 休日は11:00 - 17:00 までまんべんなく多い if 11 <= hour <= 17: visitor_count.append(np.random.randint(70, 100)) else: visitor_count.append(np.random.randint(30, 60)) else: # 平日は12時と17時が多い if hour == 12 or hour == 17: visitor_count.append(np.random.randint(50, 80)) else: visitor_count.append(np.random.randint(20, 50)) return visitor_count # 各日、各時刻の来客数をパターンに基づいて生成 for day in days_of_week: df_visitor_count.loc[day] = generate_visitor_count_with_wednesday(day)
これをR言語にChatGPT君が直訳したものがこちら。
後でベンチマークをとる関係で全体を関数化しています。
fun_for <- function() { # 乱数のシードを固定 set.seed(0) # 月曜日から日曜日までの7日間 days_of_week <- c('月', '火', '水', '木', '金', '土', '日') # 各時刻 hours_of_day <- c(10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20) # データフレームを作成 df_visitor_count <- data.frame(matrix(ncol = length(hours_of_day), nrow = length(days_of_week))) colnames(df_visitor_count) <- hours_of_day rownames(df_visitor_count) <- days_of_week # パターンに基づいて来客数を生成する関数(水曜日の特別処理を含む) generate_visitor_count_with_wednesday <- function(day) { visitor_count <- c() for (hour in hours_of_day) { if (day == '水') { # 水曜日は12時と17時以外の時間に、普段の平日より1.5倍の来客 if (hour == 12 || hour == 17) { visitor_count <- c(visitor_count, sample(50:80, 1)) } else { visitor_count <- c(visitor_count, as.integer(sample(20:50, 1) * 1.4)) } } else if (day %in% c('土', '日')) { # 休日は11:00 - 17:00 までまんべんなく多い if (11 <= hour && hour <= 17) { visitor_count <- c(visitor_count, sample(70:100, 1)) } else { visitor_count <- c(visitor_count, sample(30:60, 1)) } } else { # 平日は12時と17時が多い if (hour == 12 || hour == 17) { visitor_count <- c(visitor_count, sample(50:80, 1)) } else { visitor_count <- c(visitor_count, sample(20:50, 1)) } } } return(visitor_count) } # 各日、各時刻の来客数をパターンに基づいて生成 for (day in days_of_week) { df_visitor_count[day, ] <- generate_visitor_count_with_wednesday(day) } # データフレームを準備 df_plot <- data.frame(Hour = rep(hours_of_day, times = length(days_of_week)), Day = rep(days_of_week, each = length(hours_of_day)), Visitors = as.vector(t(df_visitor_count)))
しかし、for文を使うのはRらしくないし、sample関数で1個ずつ生成するのは如何にも効率が悪い。
そこでこんな風に書き直してみました。
sample関数は全期間分を一気に生成し、そこから条件に合ったものを取り出す形です。sample関数を何回も繰り返さない分高速化するでしょ! と思ってました。
fun_my <- function() { df_base <- expand_grid( days_of_week = c("月", "火", "水", "木", "金", "土", "日"), hours_of_day = 10:20 ) n <- nrow(df_base) set.seed(0) df_visitor_count <- df_base |> mutate( A = sample(50:80, n, replace = TRUE), #水曜日のボーナスタイム(12時、17時)以外 B = sample(20:50, n, replace = TRUE) * 1.5, #水曜日のボーナスタイム(12時、17時) C = sample(70:100, n, replace = TRUE), # 土日の11:00-17:00 D = sample(30:60, n, replace = TRUE), # 土日の他の時間 E = sample(50:80, n, replace = TRUE), # そのほかの曜日のボーナスタイム(12時、17時) F = sample(20:50, n, replace = TRUE), # そのほかの曜日のそのほかの時間 visitor_count = case_when( days_of_week == "水" & !(hours_of_day %in% c(12, 17)) ~ A, days_of_week == "水" & hours_of_day %in% c(12, 17) ~ B, days_of_week %in% c("土", "日") & hours_of_day %in% 11:17 ~ C, days_of_week %in% c("土", "日") & !(hours_of_day %in% 11:17) ~ D, !(days_of_week %in% c("水", "土", "日")) & hours_of_day %in% c(12, 17) ~ E, !(days_of_week %in% c("水", "土", "日")) & !(hours_of_day %in% c(12, 17)) ~ F ), hours_of_day = hours_of_day, days_of_week = factor(days_of_week, levels = c("月", "火", "水", "木", "金", "土", "日")) ) |> dplyr::select(days_of_week, hours_of_day, visitor_count) }
この二つの方法の実行速度をmicrobenchmarkで確認したのがこちら。
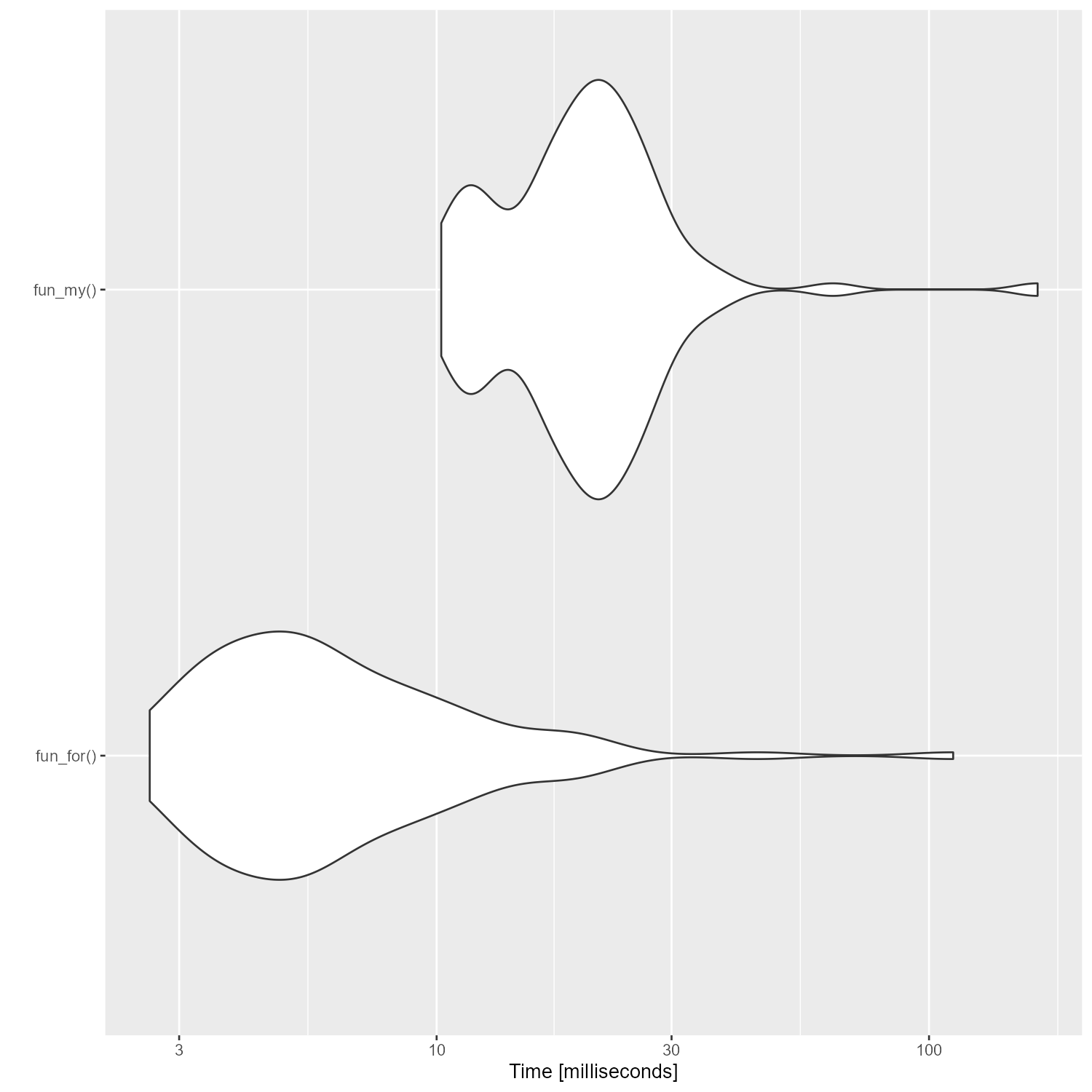
ぐぬぬ、直訳のfor文の方が速いじゃないか……
それでもfor文は使いたくないので試行錯誤した結果がこちら。
mutate()を無くしてtibble()でまとめる形にして、case_when()の中でsample()を使う形にしました。
fun_my3 <- function() { df_base <- expand_grid( days_of_week = c("月", "火", "水", "木", "金", "土", "日"), hours_of_day = 10:20 ) n <- nrow(df_base) set.seed(0) df_visitor_count <- tibble( days_of_week = factor(df_base$days_of_week, levels = c("月", "火", "水", "木", "金", "土", "日")), hours_of_day = df_base$hours_of_day, visitor_count = case_when( days_of_week == "水" & !(hours_of_day %in% c(12, 17)) ~ sample(50:80, 1), days_of_week == "水" & hours_of_day %in% c(12, 17) ~ sample(20:50, 1) * 1.5, days_of_week %in% c("土", "日") & hours_of_day %in% 11:17 ~ sample(70:100, 1), days_of_week %in% c("土", "日") & !(hours_of_day %in% 11:17) ~ sample(30:60, 1), !(days_of_week %in% c("水", "土", "日")) & hours_of_day %in% c(12, 17) ~ sample(50:80, 1), !(days_of_week %in% c("水", "土", "日")) & !(hours_of_day %in% c(12, 17)) ~ sample(20:50, 1) ) ) }
ベンチマークを取ると、なんとかfor文と同等の速さにはなった。
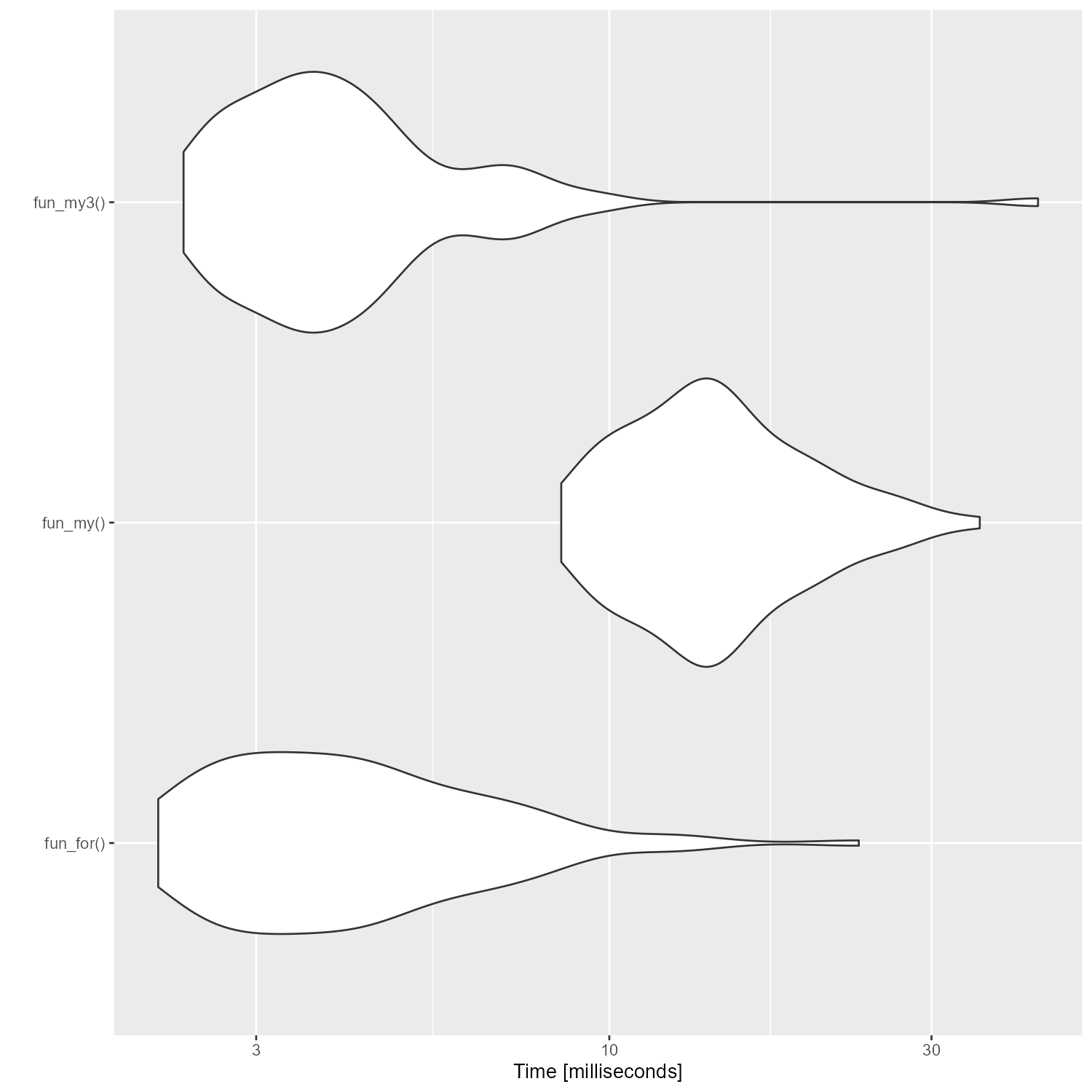
しかし、これは納得いかない。
どうすればfor文よりも高速化できるだろうか?
ネットワーク分析におけるコミュニティ抽出
この記事はR言語 Advent Calendar 2023 シリーズ2の18日目の記事です。
ネットワーク分析にコミュニティ抽出という手法があります。まあ、クラスター分析ですね。
Rのigraphパッケージには以下のコミュニティ抽出の方法が実装されています。
- ラベル伝播法 cluster_label_prop()
- ウォークトラップ cluster_walktrap()
- 辺媒介法 cluster_edge_betweenness()
- 貪欲アルゴリズム cluster_fast_greedy()
- スペクトラル最適化法 cluster_leading_eigen()
- 焼きなまし法 cluster_spinglass()
- インフォマップ法 cluster_infomap()
- ルーバン法 cluster_louvain()
- ライデン法 cluster_leiden()
どんなふうにコミュニティ抽出されるか試してみましょう。
ライブラリー呼び出し。
library(conflicted) library(tidyverse) library(igraph) library(igraphdata)
有名な空手クラブのデータで試します。
data(karate) karate |> plot()

コミュニティ抽出
cl_lp <- karate |> cluster_label_prop()# ラベル伝播法 cl_wt <- karate |> cluster_walktrap() # ウォークトラップ法 cl_eb <- karate |> cluster_edge_betweenness() # 辺媒介法 cl_fg <- karate |> cluster_fast_greedy() #貪欲アルゴリズム cl_sp <- karate |> cluster_leading_eigen() #スペクトラル最適化法 cl_sg <- karate |> cluster_spinglass() |> with_seed(1234, code=_) # 焼きなまし法 cl_im <- karate |> cluster_infomap() |> with_seed(1234, code=_) # インフォマップ法 cl_lo <- karate |> cluster_louvain() |> with_seed(1234, code=_) # ルーバン法 cl_le <- karate |> cluster_leiden() |> with_seed(1234, code=_) #ライデン法
結果を描画
plot(cl_lp, karate, main = "ラベル伝播法", layout = layout_with_kk) plot(cl_wt, karate, main = "ウォークトラップ法", layout = layout_with_kk) plot(cl_eb, karate, main = "辺媒介法", layout = layout_with_kk) plot(cl_fg, karate, main = "貪欲アルゴリズム", layout = layout_with_kk) plot(cl_sp, karate, main = "スペクトラル最適化法", layout = layout_with_kk) plot(cl_sg, karate, main = "焼きなまし法", layout = layout_with_kk) plot(cl_im, karate, main = "インフォマップ法", layout = layout_with_kk) plot(cl_lo, karate, main = "ルーバン法", layout = layout_with_kk) plot(cl_le, karate, main = "ライデン法", layout = layout_with_kk)
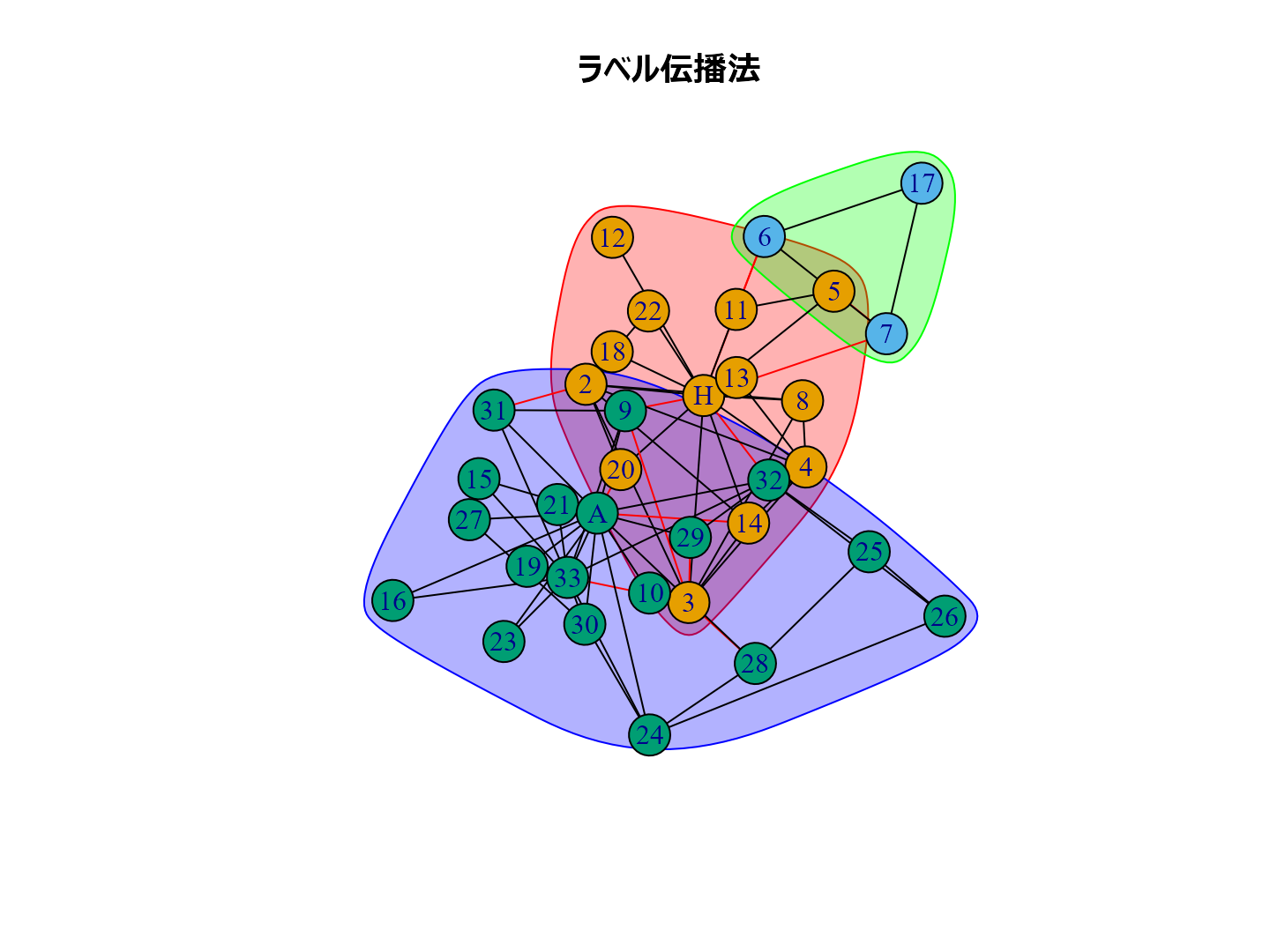


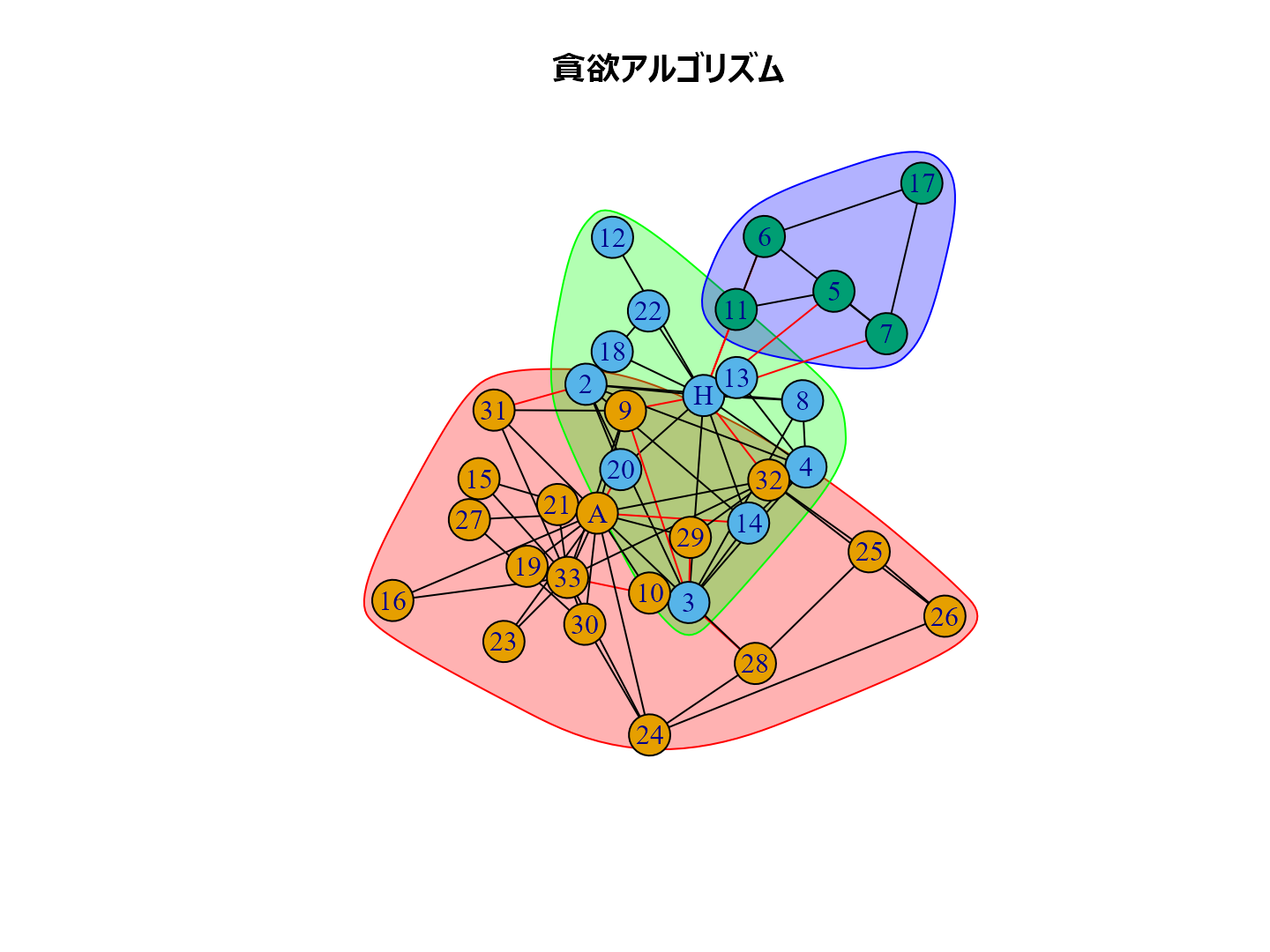



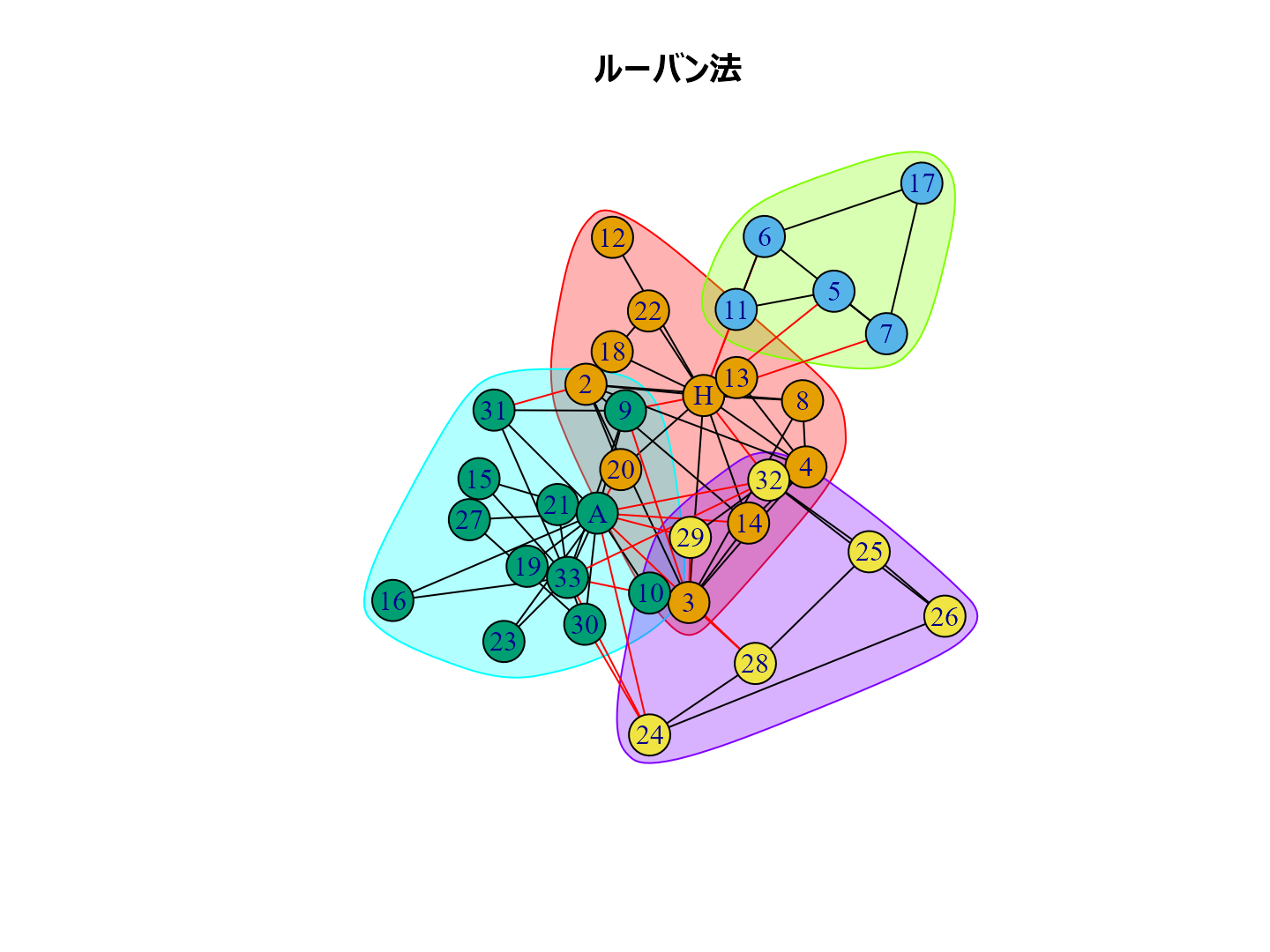
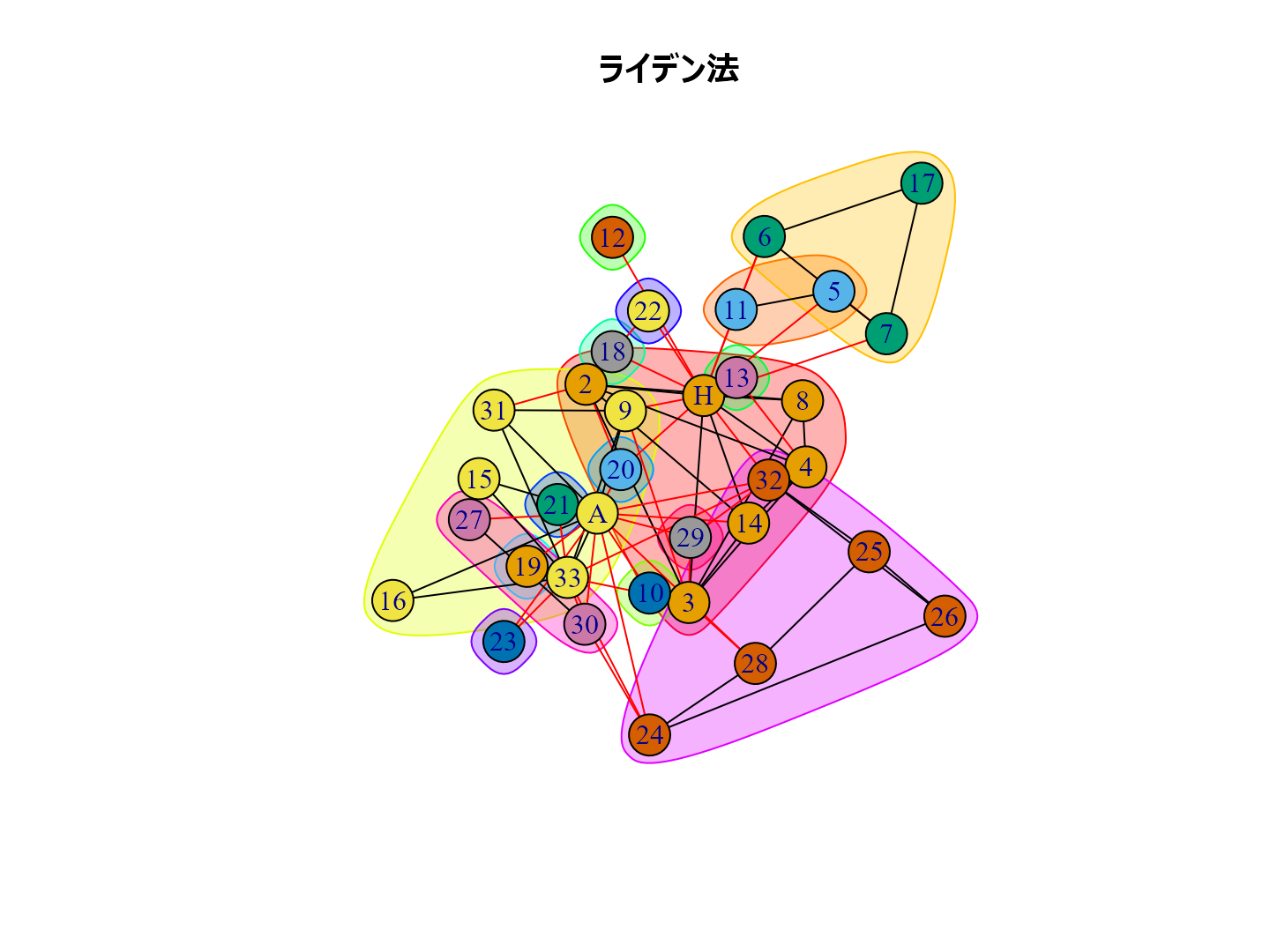
個人的な経験ではルーバン法がいい感じのグループ分けをしてくれるように思います。
Enjoy!
Rでサンタクロース
ふぉっふぉっふぉっ、みんな今年も良い子にしてたかな?
特にプレゼントはありません。
メリークリスマス!
library(conflicted) library(tidyverse) library(aplpack) library(palmerpenguins) pen_mean <- penguins |> select(bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g, species, sex) |> drop_na() |> summarise(across(where(is.numeric), \(x) mean(x)), .by = c(species, sex)) |> arrange(species, sex) faces( pen_mean |> select(bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g), labels = paste0(pen_mean$species,"_",pen_mean$sex), fill = TRUE, face.type = 2, ncol.plot = 2, main = "南極パーマー基地のサンタクロースたち" )

qeMLパッケージの紹介
qeMLパッケージの紹介
先日開催された統計数理研究所ののR研究集会(共同研究集会「データ解析環境Rの整備と利用 」)で「qeMLパッケージの紹介」というLTをしてきました。
rjpusers.connpass.com
このパッケージを知ったきっかけはtjo氏のこのツイート。
{qeML}という"Quick & Easy wrapper for Machine Learning"を謳うRパッケージが出ているのをR-Bloggersを眺めていて知って、面白そう&便利そうなので入れてみようと思ったんだけど環境設定がコケてて入らない。誰か試した人います?https://t.co/eNwAJhntRs
— TJO (@TJO_datasci) 2023年11月27日
ちなみに研究会の現場で「Macでも動いたよ!」との証言がありました。
tidymodels、caret、mlr3、superlearner、SuperMLなどよりもはるかにシンプルなインターフェイスを持つ機械学習ラッパーです。
まだまだ未完成なのですが、非常に使い勝手が良さそうなので今後の発展に期待しています。
Enjoy!
『評価指標入門』をRで書く:多クラス分類の評価指標
『評価指標入門』をRで書く
この記事はR言語 Advent Calendar 2023 シリーズ2の16日目の記事です。
多クラス分類の評価指標
パッケージの呼び出し。
library(tidyverse) library(palmerpenguins) library(rsample) library(yardstick) library(ranger)
ペンギンの種類を判別するランダムフォレストのモデル。
pen_split <- penguins |> mutate(year = as.factor(year)) |> drop_na() |> initial_split(prop = 0.2, strata = species) pen_train <- pen_split |> training() pen_test <- pen_split |> testing() fit_m_class <- pen_train |> ranger(species ~ ., data = _) pred_test <- pen_test |> predict(fit_m_class, data = _)
以下の評価指標を算出
- 正解率(Accuracy)
- 適合率(Precision ; 精度)[macro, micro, weighted]
- 再現率(Recall, True Positive Rate ; TPR ; 感度)[macro, micro, weighted]
- F1-score[macro, micro, weighted]
# 正解率(Accuracy) accuracy_vec(pen_test$species, pred_test$predictions) # 適合率(Precision ; 精度) precision_vec(pen_test$species, pred_test$predictions, estimator = "macro") precision_vec(pen_test$species, pred_test$predictions, estimator = "micro") precision_vec(pen_test$species, pred_test$predictions, estimator = "macro_weighted") # 再現率(Recall, True Positive Rate ; TPR ; 感度) recall_vec(pen_test$species, pred_test$predictions, estimator = "macro") recall_vec(pen_test$species, pred_test$predictions, estimator = "micro") recall_vec(pen_test$species, pred_test$predictions, estimator = "macro_weighted") # F1-score f_meas_vec(pen_test$species, pred_test$predictions, estimator = "macro") f_meas_vec(pen_test$species, pred_test$predictions, estimator = "micro") f_meas_vec(pen_test$species, pred_test$predictions, estimator = "macro_weighted")
ペンギンの種類の確率を推定するランダムフォレストのモデル。
fit_m_class_p <- pen_train |> ranger(species ~ ., data = _, probability = TRUE) pred_test <- pen_test |> predict(fit_m_class_p, data = _)
ROC-AUCの算出
roc_auc_vec(pen_test$species, pred_test$predictions)
以上です。
『評価指標入門』をRで書く:二値分類における評価指標
『評価指標入門』をRで書く
この記事はR言語 Advent Calendar 2023 シリーズ2の13日目の記事です。
二値分類における評価指標
ライブラリーの呼び出し。
library(tidyverse) library(palmerpenguins) library(rsample) library(MLmetrics) library(yardstick) library(pROC) library(ranger)
ペンギンの性別を判別するランダムフォレストのモデル。
pen_split <- penguins |> mutate(year = as.factor(year)) |> drop_na() |> initial_split(prop = 0.2, strata = sex) pen_train <- pen_split |> training() pen_test <- pen_split |> testing() fit_2_class <- pen_train |> ranger(sex ~ ., data = _) pred_test <- pen_test |> predict(fit_2_class, data = _)
G-Meanのパッケージが見当たらなかったので実装する。
g_mean <- function (y_true, y_pred, positive = NULL) { Confusion_DF <- ConfusionDF(y_pred, y_true) if (is.null(positive) == TRUE) positive <- as.character(Confusion_DF[1, 1]) TP <- as.integer(subset(Confusion_DF, y_true == positive & y_pred == positive)["Freq"]) FN <- as.integer(sum(subset(Confusion_DF, y_true == positive & y_pred != positive)["Freq"])) TN <- as.integer(subset(Confusion_DF, y_true != positive & y_pred != positive)["Freq"]) FP <- as.integer(sum(subset(Confusion_DF, y_true != positive & y_pred == positive)["Freq"])) TPR <- TP/(TP + FN) TNR <- TN/(TP + FP) GM <- sqrt(TPR * TNR) return(GM) }
以下の評価指標を算出。
- 正解率(Accuracy)
- マシューズ相関係数(Matthews Correlation coefficient ; MCC)
- 適合率(Precision ; 精度)
- 再現率(Recall, True Positive Rate ; TPR ; 感度)
- F1-score
- G-Mean(Geometric Mean)
Accuracy(pred_test$predictions, pen_test$sex) mcc_vec(pred_test$predictions, pen_test$sex) Precision(pred_test$predictions, pen_test$sex) Recall(pred_test$predictions, pen_test$sex) F1_Score(pred_test$predictions, pen_test$sex) g_mean(pred_test$predictions, pen_test$sex)
ペンギンの性別の確率を推定するランダムフォレストのモデル。
fit_2_class_p <- pen_train |> mutate(sex = if_else(sex == "female", 1, 0)) |> ranger(sex ~ ., data = _) pred_test <- pen_test |> mutate(sex = if_else(sex == "female", 1, 0)) |> predict(fit_2_class_p, data = _)
以下の評価指標を算出する。
- ROC-AUC(Receiver Operating Characteristic - Area Under the Curve)
- PR-AUC(Precision Recall - Area Under the Curve)
- pAUC(Partial Precision Area Under the Curve)
# ROC-AUC AUC( pred_test$predictions, if_else(pen_test$sex == "female", 1, 0) ) # PR-AUC PRAUC( pred_test$predictions, if_else(pen_test$sex == "female", 1, 0) ) # pAUC (α = 0, β = 0.2 の場合) roc( if_else(pen_test$sex == "female", 1, 0), pred_test$predictions ) |> auc(partial.auc=c(0.0, 0.2), partial.auc.correct=TRUE)
以上です。