for文を無くして高速化したいがfor文の方が速い
こちらのPythonのコードのデモデータ生成部分をR言語で再現したい。
https://github.com/tkEzaki/data_visualization/blob/main/8%E7%AB%A0/8_1_4_legend_examples.py
import pandas as pd # データフレーム操作のためのPandas import numpy as np # 数値計算のためのNumPy np.random.seed(0) # 乱数のシードを固定 # 月曜日から日曜日までの7日間 days_of_week = ['月', '火', '水', '木', '金', '土', '日'] # 各時刻 hours_of_day = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20] # データフレームを作成 df_visitor_count = pd.DataFrame(index=days_of_week, columns=hours_of_day) # パターンに基づいて来客数を生成する関数(水曜日の特別処理を含む) def generate_visitor_count_with_wednesday(day): visitor_count = [] for hour in hours_of_day: if day == '水': # 水曜日は12時と17時以外の時間に、普段の平日より1.5倍の来客 if hour == 12 or hour == 17: visitor_count.append(np.random.randint(50, 80)) else: visitor_count.append(int(np.random.randint(20, 50) * 1.4)) elif day in ['土', '日']: # 休日は11:00 - 17:00 までまんべんなく多い if 11 <= hour <= 17: visitor_count.append(np.random.randint(70, 100)) else: visitor_count.append(np.random.randint(30, 60)) else: # 平日は12時と17時が多い if hour == 12 or hour == 17: visitor_count.append(np.random.randint(50, 80)) else: visitor_count.append(np.random.randint(20, 50)) return visitor_count # 各日、各時刻の来客数をパターンに基づいて生成 for day in days_of_week: df_visitor_count.loc[day] = generate_visitor_count_with_wednesday(day)
これをR言語にChatGPT君が直訳したものがこちら。
後でベンチマークをとる関係で全体を関数化しています。
fun_for <- function() { # 乱数のシードを固定 set.seed(0) # 月曜日から日曜日までの7日間 days_of_week <- c('月', '火', '水', '木', '金', '土', '日') # 各時刻 hours_of_day <- c(10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20) # データフレームを作成 df_visitor_count <- data.frame(matrix(ncol = length(hours_of_day), nrow = length(days_of_week))) colnames(df_visitor_count) <- hours_of_day rownames(df_visitor_count) <- days_of_week # パターンに基づいて来客数を生成する関数(水曜日の特別処理を含む) generate_visitor_count_with_wednesday <- function(day) { visitor_count <- c() for (hour in hours_of_day) { if (day == '水') { # 水曜日は12時と17時以外の時間に、普段の平日より1.5倍の来客 if (hour == 12 || hour == 17) { visitor_count <- c(visitor_count, sample(50:80, 1)) } else { visitor_count <- c(visitor_count, as.integer(sample(20:50, 1) * 1.4)) } } else if (day %in% c('土', '日')) { # 休日は11:00 - 17:00 までまんべんなく多い if (11 <= hour && hour <= 17) { visitor_count <- c(visitor_count, sample(70:100, 1)) } else { visitor_count <- c(visitor_count, sample(30:60, 1)) } } else { # 平日は12時と17時が多い if (hour == 12 || hour == 17) { visitor_count <- c(visitor_count, sample(50:80, 1)) } else { visitor_count <- c(visitor_count, sample(20:50, 1)) } } } return(visitor_count) } # 各日、各時刻の来客数をパターンに基づいて生成 for (day in days_of_week) { df_visitor_count[day, ] <- generate_visitor_count_with_wednesday(day) } # データフレームを準備 df_plot <- data.frame(Hour = rep(hours_of_day, times = length(days_of_week)), Day = rep(days_of_week, each = length(hours_of_day)), Visitors = as.vector(t(df_visitor_count)))
しかし、for文を使うのはRらしくないし、sample関数で1個ずつ生成するのは如何にも効率が悪い。
そこでこんな風に書き直してみました。
sample関数は全期間分を一気に生成し、そこから条件に合ったものを取り出す形です。sample関数を何回も繰り返さない分高速化するでしょ! と思ってました。
fun_my <- function() { df_base <- expand_grid( days_of_week = c("月", "火", "水", "木", "金", "土", "日"), hours_of_day = 10:20 ) n <- nrow(df_base) set.seed(0) df_visitor_count <- df_base |> mutate( A = sample(50:80, n, replace = TRUE), #水曜日のボーナスタイム(12時、17時)以外 B = sample(20:50, n, replace = TRUE) * 1.5, #水曜日のボーナスタイム(12時、17時) C = sample(70:100, n, replace = TRUE), # 土日の11:00-17:00 D = sample(30:60, n, replace = TRUE), # 土日の他の時間 E = sample(50:80, n, replace = TRUE), # そのほかの曜日のボーナスタイム(12時、17時) F = sample(20:50, n, replace = TRUE), # そのほかの曜日のそのほかの時間 visitor_count = case_when( days_of_week == "水" & !(hours_of_day %in% c(12, 17)) ~ A, days_of_week == "水" & hours_of_day %in% c(12, 17) ~ B, days_of_week %in% c("土", "日") & hours_of_day %in% 11:17 ~ C, days_of_week %in% c("土", "日") & !(hours_of_day %in% 11:17) ~ D, !(days_of_week %in% c("水", "土", "日")) & hours_of_day %in% c(12, 17) ~ E, !(days_of_week %in% c("水", "土", "日")) & !(hours_of_day %in% c(12, 17)) ~ F ), hours_of_day = hours_of_day, days_of_week = factor(days_of_week, levels = c("月", "火", "水", "木", "金", "土", "日")) ) |> dplyr::select(days_of_week, hours_of_day, visitor_count) }
この二つの方法の実行速度をmicrobenchmarkで確認したのがこちら。
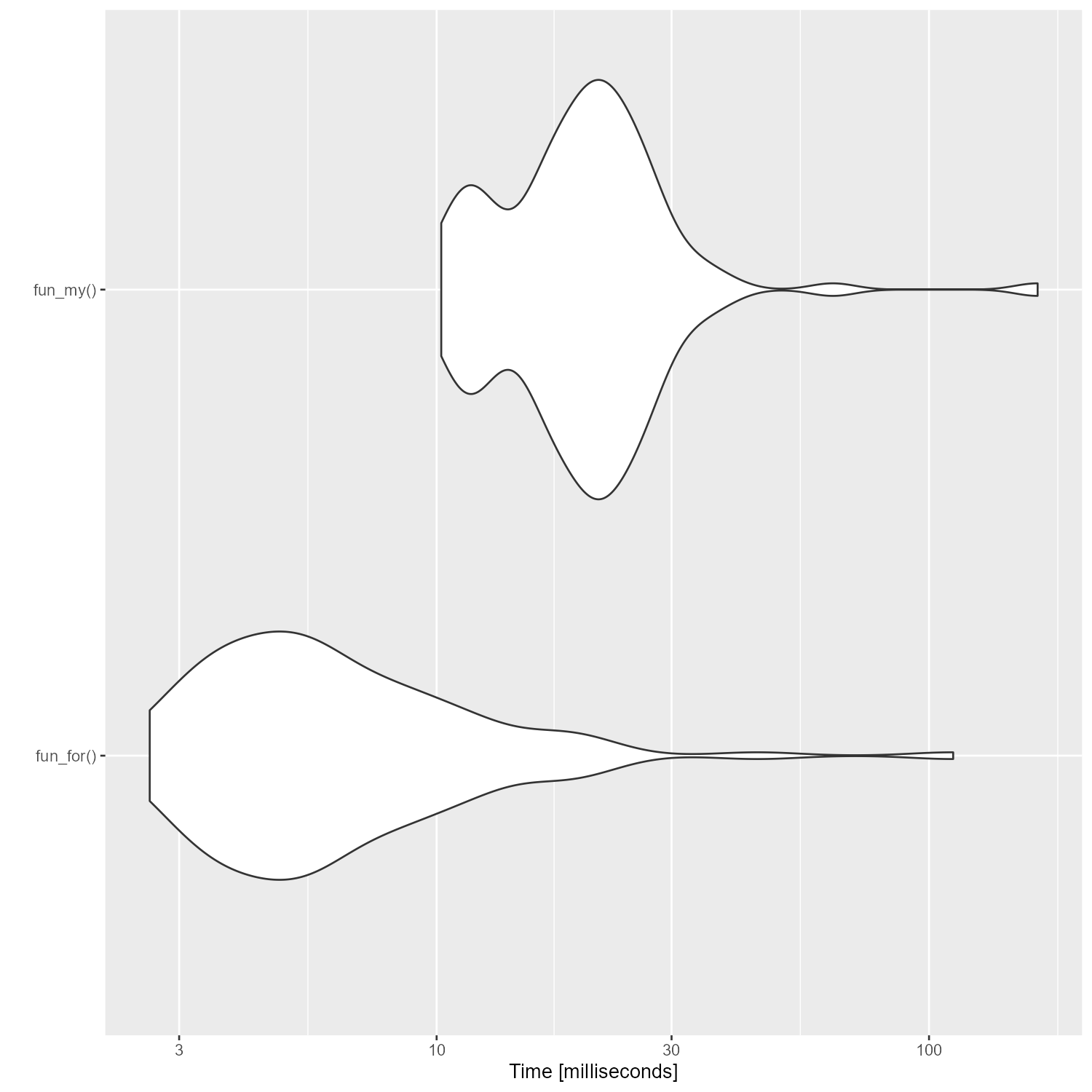
ぐぬぬ、直訳のfor文の方が速いじゃないか……
それでもfor文は使いたくないので試行錯誤した結果がこちら。
mutate()を無くしてtibble()でまとめる形にして、case_when()の中でsample()を使う形にしました。
fun_my3 <- function() { df_base <- expand_grid( days_of_week = c("月", "火", "水", "木", "金", "土", "日"), hours_of_day = 10:20 ) n <- nrow(df_base) set.seed(0) df_visitor_count <- tibble( days_of_week = factor(df_base$days_of_week, levels = c("月", "火", "水", "木", "金", "土", "日")), hours_of_day = df_base$hours_of_day, visitor_count = case_when( days_of_week == "水" & !(hours_of_day %in% c(12, 17)) ~ sample(50:80, 1), days_of_week == "水" & hours_of_day %in% c(12, 17) ~ sample(20:50, 1) * 1.5, days_of_week %in% c("土", "日") & hours_of_day %in% 11:17 ~ sample(70:100, 1), days_of_week %in% c("土", "日") & !(hours_of_day %in% 11:17) ~ sample(30:60, 1), !(days_of_week %in% c("水", "土", "日")) & hours_of_day %in% c(12, 17) ~ sample(50:80, 1), !(days_of_week %in% c("水", "土", "日")) & !(hours_of_day %in% c(12, 17)) ~ sample(20:50, 1) ) ) }
ベンチマークを取ると、なんとかfor文と同等の速さにはなった。
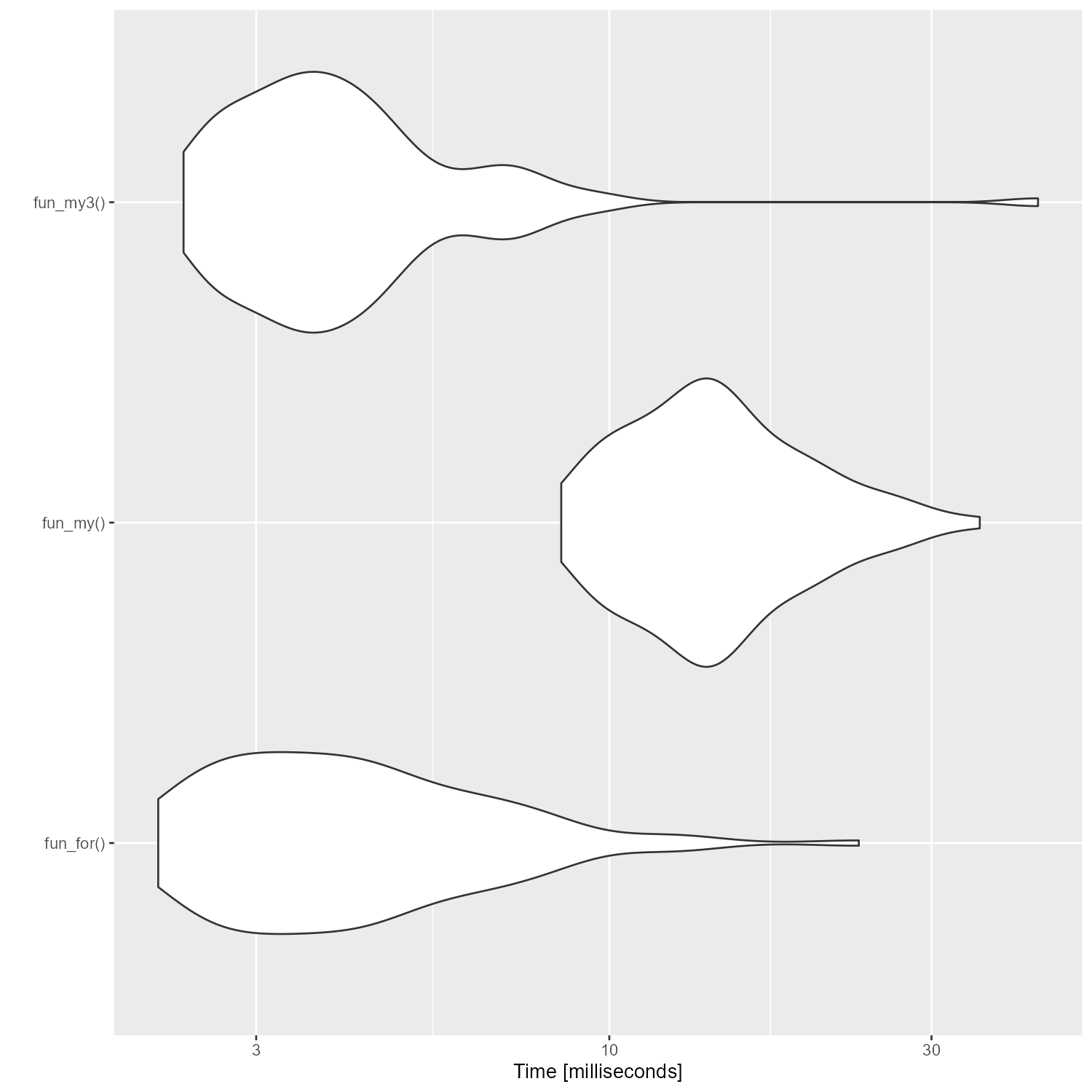
しかし、これは納得いかない。
どうすればfor文よりも高速化できるだろうか?