Tidymodelsをシンプルに使う
R言語で教師あり機械学習系の手法を使うときはこれまでcaretを使っていたのだけど、最近はTidymodelsの方が機能面で充実してきているので、そろそろ手を出さねばなるまいかと思い勉強を始めています。
本記事は現状ではTidymodelsをこんな風に使ってるよ、という中間報告です。
まちがいや非効率な部分もあるかと思うので、コメントやご指摘をいただけると幸いです。
参考にしたのは以下の記事と書籍です。(順不同)
Rユーザのためのtidymodels[実践]入門 〜モダンな統計・機械学習モデリングの世界:書籍案内|技術評論社
tidymodels講座 - データサイエンスの道標
RでもKaggle Competitions Expertになれる|igjit
tidymodelsで覚えるRでのモデル構築と運用 / tidymodels2020 - Speaker Deck
tidymodels | Atusy's blog
【R】tidymodelsとworkflowを中心に〜機械学習のフレームワーク〜(その1) - Qiita
Tidy Modeling with R
RStudio: Tidymodels, Virtually
基本的な方針は以下です。
- 細かい部分の最適化はさておき、とにかく一通り結果が出るところまで完走する。
- 可能な限りデフォルト設定で行く。
- 複数のモデルを比較し最も良いモデルを探したい。
今回は連続変数を目的変数とした回帰の事例です。二値分類、多クラス分類もいずれ書くつもり。
扱うデータセットは『Rユーザのためのtidymodels[実践]入門』でも扱われている Ames Housing Data です。
このデータセットにはアイオワ州エイムズの2,930件の物件に関する情報が含まれており、例えば以下のような変数があります。
- 家の特徴(寝室、ガレージ、暖炉、プール、ポーチなど)
- 土地情報(形状、広さなど)
- 状態や品質に関する評価
- 売却価格
このデータセットを使って売却価格をうまく推定できるモデルを構築しましょう。
最初に必要なパッケージ類を呼び出しておきます。
インストールしていないパッケージは適宜インストールしてください。
library(conflicted) # 関数名の重複対策 library(tidyverse) # データ処理全般 library(tidymodels) # 本記事の主役 library(withr) # with_seed()で乱数種を固定するため library(rpart) # 決定木(cart) library(ranger) # ランダムフォレスト library(xgboost) # XGBoost library(bonsai) # LightGBM
まずは前処理(特徴量エンジニアリング)です。以下の処理を行います。
- 事前に目的変数である売却価格に対数変換を施す。
- 学習用データと検証用データにいい感じに分割する。
- 説明変数である各変数にもダミー変数化や変数変換などの各処理を施す。
目的変数の変数変換は、後で出てくるrecipe()関数での処理も可能なのですが、skip引数周りがややこしいと感じたので事前に変換しています。
変換後のデータセットはames_logというデータフレームになります。
ames_log <- modeldata::ames |> mutate(Sale_Price_log1p = Sale_Price |> log1p()) |> # 戻すときはexpm1() select(!Sale_Price)
学習用データと検証用データに分割します。Tidymodelsでは大元のデータはできるだけ生データの形のままで持ち、前処理は必要な時点でかける考え方のようです。
initial_split()で分割情報を生成します。propで学習用データの割合を指定し、strataに目的変数を指定することでバランスよく学習用データと検証用データに分けてくれます。
実際に分割されたデータを取り出すには学習用データはtraining()、検証用データはtesting()を使います。
学習用データはames_train、検証用データはames_testという名前にしました。
ames_split <- ames_log |> initial_split(prop = 0.8, strata = "Sale_Price_log1p") |> with_seed(seed = 1234, code = _) #乱数種種の固定 # 学習用データ、検証用データの取り出し ames_train <- ames_split |> training() ames_test <- ames_split |> testing()
説明変数の前処理の設定をします。
学習用データセットames_trainをもとに、まずrecipe()関数でモデル式を指定します。
そのあと、各変数にどのような前処理を施すかstep_*()関数で指定していきます。
この前処理の設定はames_recipeという名前にします。
ames_recipe <- ames_train |> recipe(Sale_Price_log1p ~ .) |> # モデル式を指定、モデルに使う変数の指定 step_zv(all_predictors()) |> # すべての説明変数から単一の値しか持たない変数を削除 step_YeoJohnson(Lot_Area, Gr_Liv_Area) |> # Lot_Area, Gr_Liv_AreaにYJ変換 step_other(Neighborhood, threshold = 0.1) |> # 10%未満のカテゴリを「その他」に step_dummy(all_factor_predictors()) # 因子型の説明変数をダミー変数化
step_*()関数でどのような処理が可能なのか、詳細はこちらのリファレンスなどを参照してください。
参考までに、主な処理を以下に示しておきます。
- 欠損値補完
- 変数変換
- 離散化
- ダミー変数化、エンコーディング
- 標準化
- 多変量解析(次元縮約や距離)
- 変数選択
- 行選択
次に、手法の設定をします。
まず、機械学習の手法のモデルを指定します。
使えるモデルの詳細はこちらで確認できます。
以下にいくつかピックアップします。
- linear_reg(): 線形回帰
- logistic_reg(): ロジスティック回帰
- poisson_reg(): ポアソン回帰
- decision_tree(): 決定木
- bag_tree(): 決定木のアンサンブル
- rand_forest(): ランダム・フォレスト
- boost_tree(): ブースティング決定木
modeで「回帰(regression)」か「分類(classification)」かを指定します。
さらにengineで実装を指定します。
指定できる実装はshow_engines()関数で確認できます。
show_engines("boost_tree") # # A tibble: 7 × 2 # engine mode # <chr> <chr> # 1 xgboost classification # 2 xgboost regression # 3 C5.0 classification # 4 spark classification # 5 spark regression # 6 lightgbm regression # 7 lightgbm classification
決定木のboost_tree()の場合、modeが回帰であれば、xgboost 、spark、lightgbmの実装が指定できることが分かります。
今回は、決定木(cart)、ランダムフォレスト、XGBoost、LightGBMの四つのモデルを適用してみましょう。
なお、実装特有の引数はset_args()で加えることができます。
cart_model <- decision_tree(mode = "regression", engine = "rpart") |> set_args(model=TRUE) rf_model <- rand_forest(mode = "regression", engine = "ranger") |> set_args(importance = "impurity", num.threads = parallel::detectCores()) xgb_model <- boost_tree(mode = "regression", engine = "xgboost") lgb_model <- boost_tree(mode = "regression", engine = "lightgbm")
いよいよ、学習用データを各モデルに適用していきます。
まず、前処理とモデルの組み合わせを作ります。これをワークフローと呼びます。
このワークフローに学習用データを与えて学習します。
これをモデルの個数分繰り返すのは面倒なので、一連の流れを関数にまとめ、map()で一気に処理します。
お手元で再現される場合、関数の中のレシピames_recipeと学習用データames_trainはご自分のものに置き換えてください。
# 一連の流れを関数にまとめる。 workflow_temp <- function(model) { workflow() |> # ワークフロー作成の宣言 add_recipe(ames_rec) |> # レシピ(前処理、特徴量エンジニアリング)の指定 add_model(model) |> # 適用するモデルの指定 fit(data = ames_train) |> # 学習用データで学習 with_seed(seed = 1234, code = _) # 乱数種の設定 } # map()で一気に処理 wf_models <- list( cart = cart_model, rf = rf_model, xgb = xgb_model, lgb = lgb_model ) |> map(\(x) workflow_temp(x))
これでwf_modelsの中に学習済みモデルが格納されます。
では学習済みモデルに検証用データを当てはめて精度を確認しましょう。
これもモデルごとに算出するのは手間なので、一連の流れを関数化し、map()で一気に片づけます。
関数の中の検証用データames_testと目的変数Sale_Price_log1pは適宜置き換えてください。
また、目的変数は事前に対数変換していたので、ここでexpm1()で元に戻しています。
metric_temp <- function(workflow_models) { workflow_models |> augment(new_data = ames_test) |> #検証用データを当てはめた結果を検証用データにくっ付けて返す mutate( Sale_Price = expm1(Sale_Price_log1p), .pred = expm1(.pred), .keep = "none" ) |> metrics( #評価指標を返す truth = Sale_Price, estimate = .pred ) } metric_res <- wf_models |> map(\(x) metric_temp(x)) # モデルごとの評価指標を見やすい形に整形 metric_res_merge <- metric_res |> list_cbind() |> unnest(cols = metric_res |> names(), names_sep = "") |> select(1, ends_with(".estimate")) %>% # ここだけプレイスフォルダーの関係で|>じゃなく%>%になっちゃう rename_with(~ str_remove(., ".estimate")) |> rename("metric" = 1) metric_res_merge # # A tibble: 3 × 5 # metric cart rf xgb lgb # <chr> <dbl> <dbl> <dbl> <dbl> # 1 rmse 43476. 26246. 28069. 22071. # 2 rsq 0.673 0.894 0.890 0.915 # 3 mae 29835. 16293. 18638. 14067.
数表じゃ分かりにくいのでグラフにしましょう。
今回はRMSE(二乗平均平方根誤差)で判断することにします。
metric_res_merge |> pivot_longer(cols = !metric, names_to = "model") |> dplyr::filter(metric == "rmse") |> ggplot(aes(x = reorder(model, value), y = value)) + geom_col() + labs(title = "RMSE(二乗平均平方根誤差)", x = "モデル")
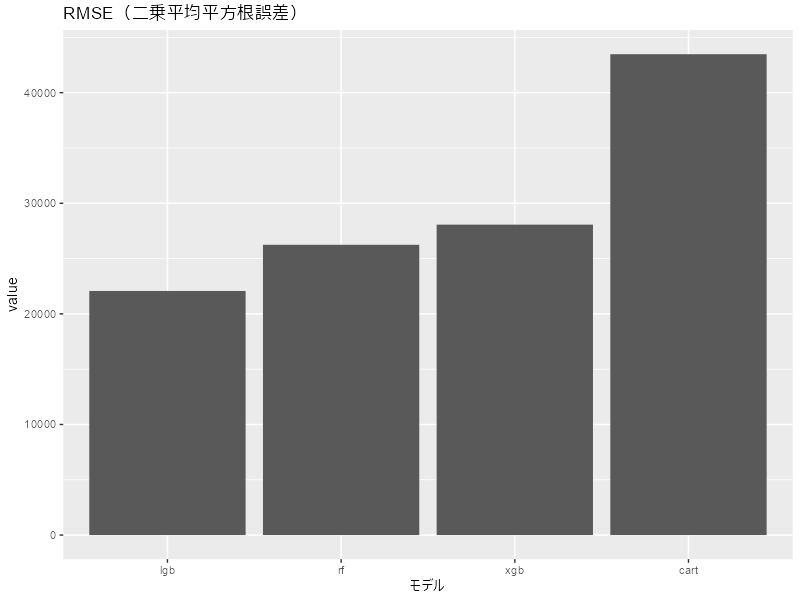
cartはダメなようです。
LightGBM、XGBoost、ランダムフォレストはドングリの背比べ?
それではLightGBM、XGBoost、ランダムフォレストについてハイパーパラメーターのチューニングを行いましょう。
以下のステップで進めます。
- チューニングに使う交差検証用のデータセット生成
- チューニング用のモデル設定
- ハイパーパラメーターの探索
まず、交差検証用のデータセットを生成します。
ここではk分割交差検証法を使います。
ames_folds <- ames_train |> vfold_cv(v = 10, strata = "Sale_Price_log1p") |> #10分割、strataに目的変数を指定 with_seed(seed = 1234, code = _) #乱数種の固定
チューニング用のモデルを設定します。
チューニングしたいパラメーターにtune()を指定します。
rf_model_tune <- rand_forest( mode = "regression", engine = "ranger", min_n = tune() ) |> set_args( # engine特有の引数はset_argsで設定 importance = "impurity", num.threads = parallel::detectCores() ) xgb_model_tune <- boost_tree( mode = "regression", engine = "xgboost", min_n = tune(), tree_depth = tune() ) lgb_model_tune <- boost_tree( mode = "regression", engine = "lightgbm", min_n = tune(), tree_depth = tune() )
いよいよチューニングの実行ですが、これもモデルの個数分実行するのは手間なので、関数化してmap()で一気に片づけます。
これも関数内のames_recipe、ames_foldsは必要に応じて置き換えてください。
ここは時間がかかります。
hp_search <- function(model) { tune_bayes(model, ames_recipe, ames_folds, metrics = metric_set(rmse)) |> with_seed(seed = 1234, code = _) } tuning_models <- list( rf_tune = rf_model_tune, xgb_tune = xgb_model_tune, lgb_tune = lgb_model_tune ) |> map(\(x) hp_search(x))
結果を確認しましょう。
best_tune <- tuning_models |> map(\(x) select_best(x, metric = "rmse")) best_tune # $rf_tune # # A tibble: 1 × 2 # min_n .config # <int> <chr> # 1 2 Iter1 # # $xgb_tune # # A tibble: 1 × 3 # min_n tree_depth .config # <int> <int> <chr> # 1 17 12 Iter3 # # $lgb_tune # # A tibble: 1 × 3 # min_n tree_depth .config # <int> <int> <chr> # 1 22 14 Iter7
各モデルで良いと思われるハイパーパラメータが出ました。
これを使ってモデルを作り直します。
rf_model_tuned <- rand_forest( mode = "regression", engine = "ranger", min_n = best_tune$rf$min_n #ここ ) |> set_args( importance = "impurity", num.threads = parallel::detectCores() ) xgb_model_tuned <- boost_tree( mode = "regression", engine = "lightgbm", min_n = best_tune$xgb$min_n, #ここ tree_depth = best_tune$xgb$tree_depth #ここ ) lgb_model_tuned <- boost_tree( mode = "regression", engine = "lightgbm", min_n = best_tune$lgb$min_n, #ここ tree_depth = best_tune$lgb$tree_depth #ここ )
そして、検証用データで精度を確認します。
wf_models_tuned <- list( cart = cart_model, rf = rf_model, rf_tuned = rf_model_tuned, xgb = xgb_model, xgb_tuned = xgb_model, lgb = lgb_model, lgb_tuned = lgb_model_tuned ) |> map(\(x) workflow_temp(x)) metric_res_tuned <- wf_models_tuned |> map(\(x) metric_temp(x)) metric_res_tuned_merge <- metric_res_tuned |> list_cbind() |> unnest(cols = metric_res_tuned |> names(), names_sep = "") |> select(1, ends_with(".estimate")) %>% # ここだけプレイスフォルダーの関係で |> じゃなく %>% を使ってる rename_with(~ str_remove(., ".estimate")) |> rename("metric" = 1) metric_res_tuned_merge # # A tibble: 3 × 8 # metric cart rf rf_tuned xgb xgb_tuned lgb lgb_tuned # <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> # 1 rmse 43476. 26246. 26100. 28069. 28069. 22071. 22408. # 2 rsq 0.673 0.894 0.896 0.890 0.890 0.915 0.912 # 3 mae 29835. 16293. 16240. 18638. 18638. 14067. 14236.
これもグラフにしましょう。
metric_res_tuned_merge |> pivot_longer(cols = !metric, names_to = "model") |> dplyr::filter(metric == "rmse") |> ggplot(aes(x = reorder(model, value), y = value)) + geom_col() + labs(title = "RMSE(二乗平均平方根誤差)", x = "モデル")
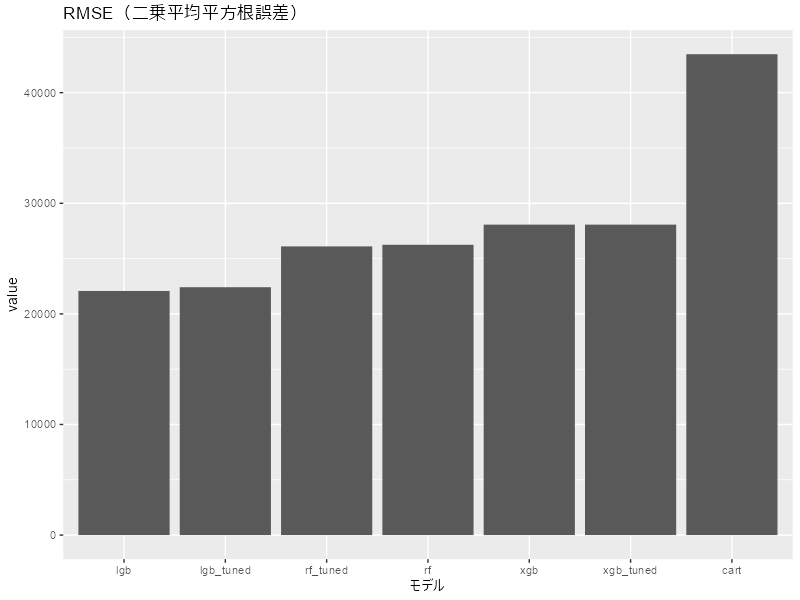
うーん、今回はチューニングしてもほとんど変わらずという結果でした。
追記:
最初の投稿では決定木のプロットがエラーになると書いたのですが、rpartのモデルに「 |> set_args(model=TRUE)」を追加したらちゃんと樹形図を描けるようになりました!
あきるさん、ご指摘ありがとうございました!
rpartの結果の決定木を描くところは、エンジンに渡される引数として`set_args(model=TRUE)`とか指定するとできると思います(手もとではそんな感じで動かせました)
— あきる (@paithiov909) 2023年4月16日
あきるさんが開発されているgibasaはテキストマイニングを支援するパッケージです!
みんな使おう!
paithiov909.github.io
あと、ぎばさは秋田の名物です!
みんなで食べよう!
ja.wikipedia.org
以上でおしまいなのですが、うまくいかなかったことが一点あります。
決定木の結果をプロットしたかったんですが、どうもこれが上手くいかない。
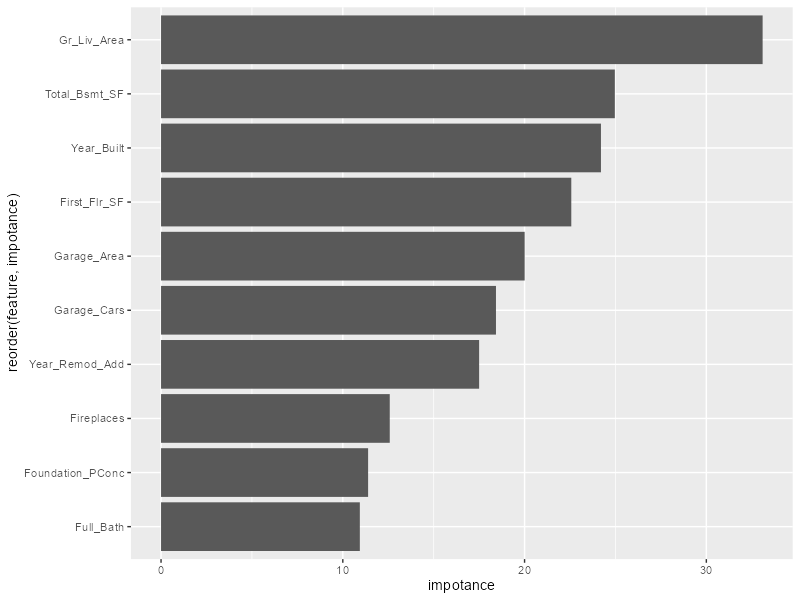
ランダムフォレストやLightGBMの重要度などは出せるので同じやり方で行けるはずなんですが、うまくいかない。
方法が分かる方がいたら教えてください。
# rfやlgbの重要度はこれで出る wf_models_tuned |> pluck("lgb_tuned", "fit", "fit", "fit") |> lgb.importance(percentage = TRUE) |> lgb.plot.importance() rf_tuned_imp <- wf_models_tuned |> pluck("rf_tuned", "fit", "fit", "fit") |> importance() tibble( feature = names(rf_tuned_imp), impotance = rf_tuned_imp ) |> slice_max(impotance, n = 10) |> ggplot(aes(y = reorder(feature, impotance), x = impotance)) + geom_col()

以下で決定木がプロットできるはずだけど、エラーになっちゃう。
rpartのモデルに「|> set_args(model=TRUE)」を追加したので、描けるようになりました!
library(partykit) wf_models_tuned |> pluck("cart", "fit", "fit", "fit") |> as.party() |> plot() # Error in model.frame.default(formula = ..y ~ Lot_Frontage + Lot_Area + : # 'data' must be a data.frame, environment, or list

以上です。
なんとかcaretは卒業してTidymodelsを使いこなせるようになりたいものです。