『データ可視化学入門』をRで書く 1.2 可視化の効果を考える
1.2 可視化の効果を考える
この記事はR言語 Advent Calendar 2023 シリーズ2の2日目の記事です。
qiita.com
1.2.1 文字情報と視覚情報による提示の違い
##### 1.2.1 ##### library(tidyverse) library(patchwork) # データフレームの作成 df <- data.frame( Country = c("日本", "ブラジル", "米国", "中国"), # 国のリスト Population = c(124620000, 215802222, 335540000, 1425849288) / 100000000 # 人口のリスト ) # 米国と日本のみを含む棒グラフの描画 p1 <- df |> dplyr::filter(Country %in% c("米国","日本")) |> arrange(desc(Population)) |> ggplot(aes(x = Population, y = reorder(Country, Population))) + geom_col() + labs(x = "人口[億人]", y = "国名") # 四か国を含む棒グラフの描画 p2 <- df |> arrange(desc(Population)) |> ggplot(aes(x = Population, y = reorder(Country, Population))) + geom_col() + labs(x = "人口[億人]", y = "国名") p1 / p2
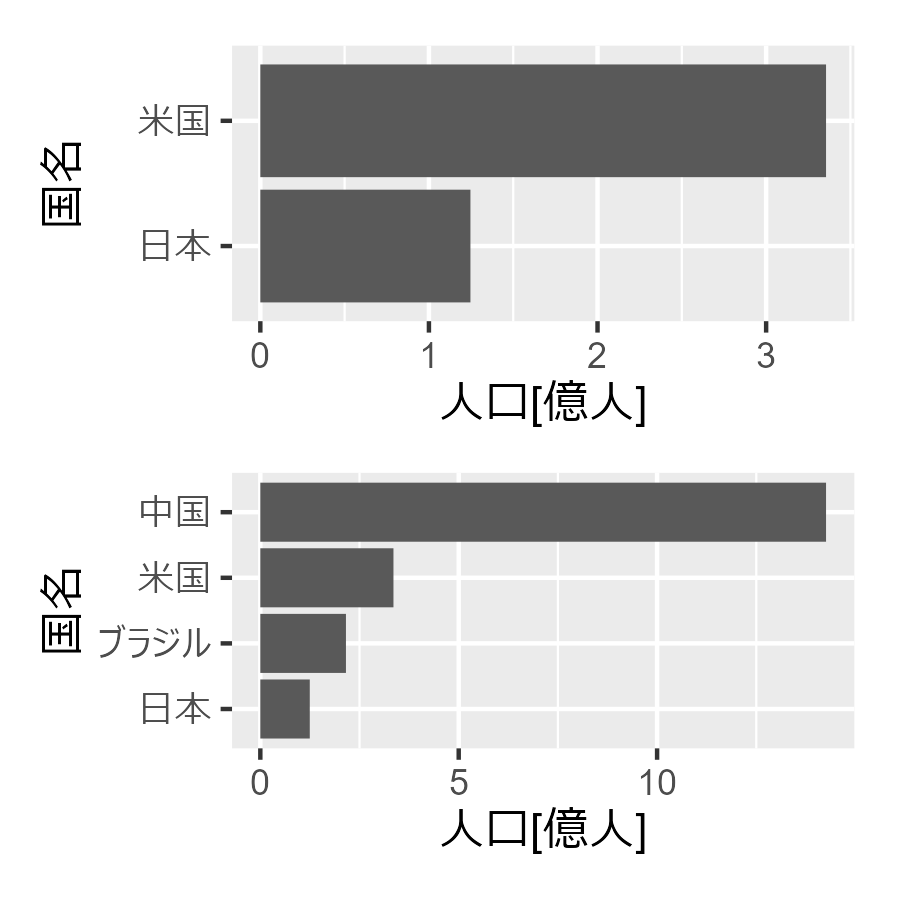
1.2.2 2変数データにおけるパターンの発見
##### 1.2.2 ##### data <- data.frame( x = c(0.204, 1.07, -0.296, 0.57, 0.637, 0.82, 0.137, -0.046), y = c(0.07, 0.57, 0.936, 1.436, 0.32, 1.003, 1.186, 0.503) ) square_points <- data.frame( x = c(-0.296, 0.57, 1.07, 0.204, -0.296), y = c(0.936, 1.436,0.57,0.07, 0.936) ) ggplot(data, aes(x = x, y = y)) + geom_point() + geom_path(square_points, mapping = aes(x = x, y = y), color = "red", linetype = "dashed") + coord_fixed() + labs(title = "視覚情報による提示")

1.2.3 重要なつながりだけ抜き出す
これはうまくできていない。
都道府県コード順に円環状に並べる方法が分からない。
library(tidyverse) library(igraph) pref_ja <- c( "北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島", "茨城", "栃木", "群馬", "埼玉", "千葉", "東京", "神奈川", "新潟", "富山", "石川", "福井", "山梨", "長野", "岐阜", "静岡", "愛知", "三重", "滋賀", "京都", "大阪", "兵庫", "奈良", "和歌山", "鳥取", "島根", "岡山", "広島", "山口", "徳島", "香川", "愛媛", "高知", "福岡", "佐賀", "長崎", "熊本", "大分", "宮崎", "鹿児島", "沖縄" ) # データをロード data_df <- read_csv( "https://raw.githubusercontent.com/tkEzaki/data_visualization/main/1%E7%AB%A0/data/matrix.csv" ) # 前処理 data_matrix <- data_df[, -1] |> as.matrix(nrow = 47) diag(data_matrix) <- 0 data_matrix <- log1p(data_matrix) rownames(data_matrix) <- colnames(data_matrix) <- pref_ja # しきい値を計算 threshold <- quantile(data_matrix, .95) # しきい値をもとにグラフデータを作る gData <- data_matrix |> as.data.frame() |> rownames_to_column(var = "pref") |> pivot_longer(!pref) |> rename( from = pref, to = name, weight = value ) |> dplyr::filter(weight >= threshold) # グラフオブジェクトを生成 g <- graph_from_data_frame(gData, directed=TRUE) E(g)$width <- E(g)$weight/5 E(g)$color <- rainbow(100, alpha = 0.5)[round(E(g)$weight/max(E(g)$weight) * 100, 0)] V(g)$label.cex <- 0.5 V(g)$size <- 10 g |> plot( layout = layout_in_circle, edge.curved = 0.5, edge.arrow.size = 0.5 )

1.2.4 全体の関係性パターンを見つける
この図は書籍だと、ラベルが都道府県コード順になっているが、クラスタリングの結果なのでそんなはずはない。
誤植と思われる。
##### 1.2.4 ##### library(tidyverse) library(pheatmap) jet.colors <- colorRampPalette(c("#00007F", "blue", "#007FFF", "cyan", "#7FFF7F", "yellow", "#FF7F00", "red", "#7F0000")) pref_ja <- c( "北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島", "茨城", "栃木", "群馬", "埼玉", "千葉", "東京", "神奈川", "新潟", "富山", "石川", "福井", "山梨", "長野", "岐阜", "静岡", "愛知", "三重", "滋賀", "京都", "大阪", "兵庫", "奈良", "和歌山", "鳥取", "島根", "岡山", "広島", "山口", "徳島", "香川", "愛媛", "高知", "福岡", "佐賀", "長崎", "熊本", "大分", "宮崎", "鹿児島", "沖縄" ) # データをロード data_df <- read_csv( "https://raw.githubusercontent.com/tkEzaki/data_visualization/main/1%E7%AB%A0/data/matrix.csv" ) # 前処理 data_matrix <- data_df[, -1] |> as.matrix(nrow = 47) data_matrix <- log1p(data_matrix) rownames(data_matrix) <- colnames(data_matrix) <- pref_ja # ヒートマップ pheatmap( data_matrix, clustering_distance_rows = "euclidean", clustering_method = "ward.D2", border_color = NA, color = jet.colors(50) )

1.2.5 様々なデータの並べ方
ここは1.2.5と1.2.6をまとめて。
棒グラフの色をグラデーションにしたのはこちらのアレンジ。
library(tidyverse) library(patchwork) # データ data_df <- data.frame( code = 1:47, prefectures = c( "北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島", "茨城", "栃木", "群馬", "埼玉", "千葉", "東京", "神奈川", "新潟", "富山", "石川", "福井", "山梨", "長野", "岐阜", "静岡", "愛知", "三重", "滋賀", "京都", "大阪", "兵庫", "奈良", "和歌山", "鳥取", "島根", "岡山", "広島", "山口", "徳島", "香川", "愛媛", "高知", "福岡", "佐賀", "長崎", "熊本", "大分", "宮崎", "鹿児島", "沖縄" ), shipments = c( 42334, 31897, 56667, 177842, 31295, 39663, 110027, 307752, 173267, 186811, 579061, 299455, 580563, 368026, 83590, 79298, 42741, 53484, 99220, 136407, 190720, 240332, 568222, 159106, 136137, 110115, 432778, 291430, 136335, 35777, 37678, 22612, 108003, 176715, 65910, 29745, 48454, 49767, 20554, 181309, 95824, 34208, 66604, 41907, 37888, 44466, 5240 )/1000 # 桁が大きいので千t単位に調整 ) # 棒グラフ # 五十音順は割愛、出荷量順を追加 # 出荷量に応じてグラデーションを追加 p1 <- data_df |> ggplot(aes(x = reorder(prefectures, code), y = shipments, fill = shipments)) + geom_col() + labs(x = "", y = "出荷量[千t]", title = "都道府県コード順") + scale_fill_gradient(low = "blue", high = "red") + theme( axis.text.x = element_text(angle = 270, hjust = 1), aspect.ratio = 1/3, legend.position = "none" ) #縦横比 p2 <- data_df |> ggplot(aes(x = reorder(prefectures, desc(shipments)), y = shipments, fill = shipments)) + geom_col() + labs(x = "", y = "出荷量[千t]", title = "出荷量順") + scale_fill_gradient(low = "blue", high = "red") + theme( axis.text.x = element_text(angle = 270, hjust = 1), aspect.ratio = 1/3, legend.position = "none" ) p1 / p2

北海道をずらすのは手間なので割愛。
#地図にデータを可視化する library(NipponMap) jet.colors <- colorRampPalette(c("#00007F", "blue", "#007FFF", "cyan", "#7FFF7F", "yellow", "#FF7F00", "red", "#7F0000")) data_df <- data_df |> mutate( col_num = round(log(shipments)/max(log(shipments))*100), col_name = jet.colors(100)[col_num] ) JapanPrefMap(col = data_df$col_name)

第1章2節は以上。
『データ可視化学入門』をRで書く 1.1 データを可視化するということ
『データ可視化学入門』をRで書く
この記事はR言語 Advent Calendar 2023 シリーズ2の1日目の記事です。
qiita.com
はじめに
2023年の12月に『指標・特徴量の設計から始めるデータ可視化学入門 データを洞察につなげる技術』という本が出まして、これがなかなか良い本でした。
いわゆるグラフやチャートについての本ですが、よくある棒グラフや折れ線グラフだけでなく、箱髭図やネットワーク図までカバーされていて勉強になります。

グラフ描画のためのコードもgithubで公開されていてすぐに実践できます。
……しかし、このコードはPyhtonなのですよねぇ。
いやいや、可視化ならRでしょ!
というわけで。『データ可視化学入門』をRで書いてみます。
とりあえず第3章まで、節ごとに記事を分けて投稿します。
1.1 データを可視化するということ
1.1.3 日本の総人口の推移
##### 1.1.3 ##### library(tidyverse) data.frame( year = 1990:2022, population = c( 1.23611, 1.24101, 1.24567, 1.24938, 1.25265, 1.2557, 1.25859, 1.26157, 1.26472, 1.26667, 1.26926, 1.27316, 1.27486, 1.27694, 1.27787, 1.27768, 1.27901, 1.28033, 1.28084, 1.28032, 1.28057, 1.27834, 1.27593, 1.27414, 1.27237, 1.27095, 1.27042, 1.26919, 1.26749, 1.26555, 1.26146, 1.25502, 1.24947 ) ) |> ggplot(aes(x = year, y = population)) + geom_line() + geom_point() + labs( x = "西暦", y = "日本の総人口 [億人]", title = "時間遷移を折れ線グラフで描画する" ) + theme(aspect.ratio = 3/5) #縦横比

1.1.4 散布図で見る総人口
##### 1.1.4 ##### library(tidyverse) data.frame( year = 1990:2022, population = c( 1.23611, 1.24101, 1.24567, 1.24938, 1.25265, 1.2557, 1.25859, 1.26157, 1.26472, 1.26667, 1.26926, 1.27316, 1.27486, 1.27694, 1.27787, 1.27768, 1.27901, 1.28033, 1.28084, 1.28032, 1.28057, 1.27834, 1.27593, 1.27414, 1.27237, 1.27095, 1.27042, 1.26919, 1.26749, 1.26555, 1.26146, 1.25502, 1.24947 ) ) |> mutate(next_year_population = lead(population)) |> # 次の年の人口列を追加 drop_na() |> # 最後の行を削除(次の年の値がないため ggplot(aes(x = population, y = next_year_population)) + geom_point() + labs( x = "ある年の日本の総人口 [億人]", y = "次の年の日本の総人口 [億人]", title = "日本の総人口の前年比較" ) + coord_cartesian(xlim = c(1.23, 1.29), ylim = c(1.23, 1.29)) + theme(aspect.ratio = 1) #縦横比

1.1.5 折れ線グラフと散布図による可視化例 その2
##### 1.1.5 ##### library(tidyverse) library(patchwork) # データの定義 data <- data.frame( t = 0:100, x_t = c( 0.2, 0.64, 0.9216, 0.28901376, 0.821939226, 0.585420539, 0.970813326, 0.113339247, 0.401973849, 0.961563495, 0.14783656, 0.503923646, 0.99993842, 0.000246305, 0.000984976, 0.003936025, 0.015682131, 0.061744808, 0.231729548, 0.712123859, 0.820013873, 0.590364483, 0.967337041, 0.126384362, 0.441645421, 0.986378972, 0.053741981, 0.203415122, 0.648149641, 0.912206736, 0.320342428, 0.870892628, 0.449754634, 0.989901613, 0.039985639, 0.153547151, 0.519881693, 0.998418873, 0.006314507, 0.025098538, 0.097874404, 0.35318002, 0.913775574, 0.315159096, 0.863335361, 0.471949661, 0.996852714, 0.012549522, 0.049568127, 0.188444511, 0.611732709, 0.950063207, 0.189772438, 0.61503544, 0.94706739, 0.200522995, 0.641254094, 0.920189124, 0.293764402, 0.829867512, 0.564749697, 0.983229907, 0.065955428, 0.246421239, 0.742791249, 0.764209638, 0.720773069, 0.805037009, 0.627809693, 0.934658729, 0.244287156, 0.738443765, 0.772578283, 0.702804318, 0.835481634, 0.549808293, 0.990076536, 0.039299956, 0.151021877, 0.512857079, 0.999338782, 0.002643123, 0.010544547, 0.041733437, 0.15996703, 0.537510318, 0.994371904, 0.022385682, 0.087538253, 0.319501229, 0.869680775, 0.4533445, 0.991293057, 0.034524528, 0.13333034, 0.462213442, 0.994288704, 0.022714708, 0.088795, 0.323641792, 0.87559113 ) ) |> mutate(lag_x_t = dplyr::lag(x_t)) p1 <- data |> ggplot(aes(x = t, y = x_t)) + geom_line() + geom_point() + labs( x = expression(italic(t)), y = expression(italic({x[t]})), title = "折れ線グラフによる可視化" ) + theme(aspect.ratio = 4/5) #縦横比 p2 <- data |> drop_na() |> ggplot(aes(x = lag_x_t, y = x_t)) + geom_point() + labs( x = expression(italic({x[t]})), y = expression(italic({x[t+1]})), title = "散布図による可視化" ) + theme(aspect.ratio = 4/5) #縦横比 # 描画レイアウトの設定と表示 p1 + p2

1.1.6 2個体間の類似度のスコア化の仮想的な例
##### 1.1.6 ##### library(tidyverse) library(mvtnorm) # 個体の位置データ set.seed(0) individual <- matrix(abs(rnorm(200)), ncol = 2) # 個体1のデータ生成 individual1 <- individual[,1] / sum(individual[, 1]) # 個体2のデータ生成 individual2 <- individual[, 1] * 0.6 + individual[, 2] * 0.4 individual2 <- individual2 / sum(individual2) df <- data.frame( 個体X = individual1, 個体Y = individual2 ) ##### 1.1.6.1 ##### df |> pivot_longer(everything()) |> mutate(X2 = rep(c(1:100), 2)) |> ggplot(aes(x = X2, y = value, fill = name)) + geom_col() + scale_fill_manual(values = c( "red","blue")) + labs( x = "滞在した場所ID", y = "滞在時間割合", title = "2個体の「行動」がどれだけ似ているか", fill = "" ) + theme(aspect.ratio = 1/2) #縦横比 ##### 1.1.6.2 ##### df |> ggplot(aes(x = 個体X, y = 個体Y)) + geom_point(alpha = 0.5) + geom_smooth(method = "lm", se = FALSE) + labs(x = "個体Xの行動データ", y = "個体Yの行動データ") + coord_fixed() # アスペクト比を等しく設定 # ヒートマップを生成 # 2変量正規分布からデータ生成 x <- rmvnorm( n = 100, mean = c(0, 0), sigma = matrix(c(1, 0.8, 0.8, 1), nrow = 2) ) # 正規化関数 my_std <- function(x) { (x - min(x)) / (max(x) - min(x)) } # 正規化実行 x1 <- my_std(x[, 1]) x2 <- my_std(x[, 2]) # ヒートマップ用のデータ分割 heatmap1 <- matrix(x1, nrow = 10, ncol = 10) heatmap2 <- matrix(x2, nrow = 10, ncol = 10) ##### 1.1.6.3 ##### # ヒートマップ描画 hm1 <- heatmap1 |> as.data.frame() |> pivot_longer(everything()) |> mutate(name2 = paste0("W", sort(rep(1:10, 10)))) |> ggplot(aes(x = name, y = name2, fill = value)) + geom_tile() + scale_fill_gradientn("value", colours = gray.colors(12, start = 0, end = 1, gamma = 2.2, alpha = 1)) + theme( aspect.ratio = 1, axis.text = element_blank(), axis.title = element_blank(), axis.ticks = element_blank(), legend.position = "none" ) + labs(title = "個体Xの見た目データ") hm2 <- heatmap2 |> as.data.frame() |> pivot_longer(everything()) |> mutate(name2 = paste0("W", sort(rep(1:10, 10)))) |> ggplot(aes(x = name, y = name2, fill = value)) + geom_tile() + scale_fill_gradientn("value", colours = gray.colors(12, start = 0, end = 1, gamma = 2.2, alpha = 1)) + theme( aspect.ratio = 1, axis.text = element_blank(), axis.title = element_blank(), axis.ticks = element_blank(), legend.position = "none" ) + labs(title = "個体Yの見た目データ") hm1 + hm2 ##### 1.1.6.4 ##### data.frame(x1, x2) |> ggplot(aes(x = x1, y = x2)) + geom_point(alpha = 0.5) + geom_smooth(method = "lm", se = FALSE, color = "blue") + labs(x = "個体Xの見た目データ", y = "個体Yの見た目データ") + coord_fixed() + # アスペクト比を等しく設定 scale_x_continuous(limits = c(0,1)) + scale_y_continuous(limits = c(0,1))




1.1.7 二つの類似度スコアの関係
##### 1.1.7 ##### library(tidyverse) library(MASS) set.seed(0) n <- 190 # データ点の数 low <- -0.45 # データの範囲の下限 high <- 0.95 # データの範囲の上限 rho <- 0.7 # 相関係数 mean <- c(0, 0) # 平均(二変数) Sigma <- matrix(c(1, rho, rho, 1), nrow=2) # 共分散行列 data <- mvrnorm(n = n-1, mu = mean, Sigma = Sigma) # 多変量正規分布からデータ生成 x <- data[,1] y <- data[,2] x <- low + (high - low) * (x - min(x)) / (max(x) - min(x)) # xデータの正規化 y <- low + (high - low) * (y - min(y)) / (max(y) - min(y)) # yデータの正規化 x <- c(x, 0.80) # 特定の点を追加 y <- c(y, 0.72) # 特定の点を追加 df <- data.frame(x = x, y = y) df |> ggplot(aes(x = x, y = y)) + geom_point(alpha = 0.5) + # 散布図の描画 geom_smooth(method = "lm", se = FALSE) + # 回帰直線の描画 geom_point(aes(x = 0.80, y = 0.72), colour = "red", size = 2) + # 特定の点を赤色で描画 coord_fixed() + # アスペクト比を等しく設定 annotate( "text", x=-0.25, y=0.75, size = 4, label=paste0("r = ", round(cor(df$x, df$y), 2)) ) + labs( x = "個体間の見た目類似度スコア", y = "個体間の行動類似度スコア", title = "2つの類似度スコアの関係" )

1書1節は以上。
Rユーザーの9割が知らない高速化の禁断の裏技!!!
この記事はR言語 Advent Calendar 2023の8日目の記事です。
qiita.com
本当に9割が知らないかどうかは知らないです。
「R言語は遅い」と言われがちですよね。
個人的には困るほど遅いと感じたことは無いのですが、まあ速いに越したことはありません。
高速化のテクニックも色々あります。
予算がある場合はメモリとCPUを強化するのが手っ取り早いです。
qiita.com
データの読み書きならreadrパッケージでも十分早いし、arrowパッケージという手もあります。
heavywatal.github.io
qiita.com
追記:for文をlapply()やReduce()で高速化する方法もあります!
qiita.com
各種処理ではとにかくベクトル化することが高速化のコツになります。
ベクトル化してください。
ベクトル化しろっつってんだろ。
また、並列化が有効なケースもあるでしょう。
www.slideshare.net
ベクトル化以外にもっと劇的に高速化する方法は無いものでしょうか?
そこで!
禁断の!!
裏技を!!!
使います!!!!
というほどでもないのですが、まあちょっと「自己責任でね!」という感じの技があります。
古より伝わる秘儀BLASの入れ替えです。
まずこちらから最新版のOpenBLASをダウンロードします。
自分のマシンに合ったものをダウンロードしてください。
解凍してできたbinフォルダの中のlibopenblas.dllというファイルがあります。これをRのbinフォルダにあるRblas.dllと入れ替えます。
不具合が出る可能性もあるので元のRblas.dllは適当にリネームして残しておきましょう。
そしてlibopenblas.dllをRblas.dllがあったフォルダに移動させ、「Rblas.dll」にリネームします。
これで完了です。Rを起動してみましょう。
私の環境では以下のように行列計算が約35倍も高速化しました。
素のR。
x <- matrix(rnorm(9000000),3000,3000) system.time(tmp <- x %*% x) # ユーザ システム 経過 # 26.74 0.31 27.82
OpenBLASに差し替え。
x <- matrix(rnorm(9000000),3000,3000) system.time(tmp <- x %*% x) # ユーザ システム 経過 # 2.56 0.15 0.80
非公式な方法ですし不具合が出る可能性もありますのであくまでも自己責任でということになりますが、Rの遅さにお悩みの方は試してみてもいいんじゃないでしょうか。
元ネタはこちらです。
www.bilibili.com
Enjoy!
正則化項付き線形回帰は真の偏回帰係数を推定しているのか?
最近、正則化項付き線形回帰についてちょっと調べてます。
それで以下の記事が気になりました。
どちらも人工データを用いて、真の偏回帰係数を正則化項付き線形回帰で推定できるか?というシミュレーションをされています。
これは非常に興味深いので自分でもやってみようと思います。
先の記事はどちらもPythonを使われてましたが、私はR言語でやってみます。
試すのは以下の5つの手法です。
- 線形回帰
- Ridge回帰
- LASSO回帰
- 適応的LASSO回帰
- Elastic net回帰
確認したいのは真の偏回帰係数に対する推定された偏回帰係数の分布です、
準備
まず下準備として、必要なパッケージの呼び出しと、必要な関数の定義をします。
パッケージの呼び出し。
if (!require("pacman")) {install.packages("pacman")}
pacman::p_load(conflicted, tidyverse, glmnetUtils)λをAICcで決める関数。RidgeとLASSO用。
AICc_glmnet <- function(glmnet_model) { tLL <- glmnet_model$nulldev - deviance(glmnet_model) k <- glmnet_model$df n <- glmnet_model$nobs df <- tibble( lambda = glmnet_model$lambda, AICc = -tLL + 2 * k + 2 * k * (k + 1) / (n - k - 1) ) best_AICc_lambda <- df|> slice_min(AICc) |> pull(lambda) return( list( best_AICc_lambda = best_AICc_lambda, AICc = df$AICc ) ) }
αとλをAICcで決める関数。Elastic net用。
get_ic_best_alpha_lambda <- function(cva_model) { n <- cva_model$alpha |> length() ics <- map( 1:n, \(list_no) cva_model |> pluck("modlist", list_no, "glmnet.fit") |> AICc_glmnet() ) df_ic <- map( 1:n, \(list_no) data.frame( best_alpah = cva_model |> pluck("alpha", list_no), best_lambda = cva_model |> pluck("modlist", list_no, "lambda"), AICc = ics |> pluck(list_no, "AICc") ) ) |> list_rbind() df_ic_best <- list( AICc_best_alpha = df_ic |> slice_min(AICc) |> pull(best_alpah), AICc_best_lambda = df_ic |> slice_min(AICc) |> pull(best_lambda) ) return(df_ic_best) } || そして、シミュレーションを回す関数。 指定した説明変数の数とサンプルサイズのダミーデータを生成し、各手法に当てはめてそれぞれの偏回帰係数を出力します。 >|r| # sim_f(N, K, seed) # N: サンプルサイズ # K: 変数の数 # seed: 再現のための乱数種 sim_f <- function(N, K, seed) { set.seed(seed) X <- MASS::mvrnorm(N, mu = rep(0, K), Sigma = diag(K)) Y <- X %*% beta + rnorm(N) df <- X |> as.data.frame() |> bind_cols(data.frame(Y = Y)) # lm coef_lm <- lm(Y ~ ., data = df) |> broom::tidy() |> slice(-1) |> select(term, estimate) # Ridge ridge_best_lambda <- glmnet(Y ~ ., data = df, alpha = 0) |> AICc_glmnet() coef_ridge <- glmnet(Y ~ ., data = df, alpha = 0, lambda = ridge_best_lambda$best_AICc_lambda) |> broom::tidy() |> slice(-1) |> select(term, estimate) # LASSO lasso_best_lambda <- glmnet(Y ~ ., data = df, alpha = 1) |> AICc_glmnet() coef_lasso <- glmnet(Y ~ ., data = df, alpha = 1, lambda = lasso_best_lambda$best_AICc_lambda) |> broom::tidy() |> slice(-1) |> select(term, estimate) # 適応的LASSO coef_alasso <- glmnet(Y ~ ., data = df, alpha = 1, lambda = 5 / nrow(df)^(3 / 4), penalty.factor = 1 / abs(coef_lm$estimate) ) |> broom::tidy() |> slice(-1) |> select(term, estimate) # EN EN_best_alpha_lambda <- cva.glmnet(Y ~ ., data = df) |> get_ic_best_alpha_lambda() coef_EN <- glmnet(Y ~ ., data = df, alpha = EN_best_alpha_lambda$AICc_best_alpha, lambda = EN_best_alpha_lambda$AICc_best_lambda) |> broom::tidy() |> slice(-1) |> select(term, estimate) # res res <- coef_lm |> left_join(coef_ridge, by = join_by(term)) |> left_join(coef_lasso, by = join_by(term)) |> left_join(coef_alasso, by = join_by(term)) |> left_join(coef_EN, by = join_by(term)) |> rename( lm = estimate.x, ridge = estimate.y, lasso = estimate.x.x, alasso = estimate.y.y, EN = estimate ) return(res) }
これで準備完了です。
素直なデータセット
まずは素直なデータセットで試してみます。
説明変数5個、サンプルサイズ100です。
それぞれの真の偏回帰係数は-1, -0.5, 0, 0.5, 1です。
線形回帰は真の偏回帰係数を中心に分布していて、バラツキも小さくいい感じです。
正則化項付き回帰はいずれも過小推定の傾向があり、真の偏回帰係数をうまく推定できているとは言えそうにありません。

K <- 5 N <- 100 I <- 300 # 試行回数 beta <- seq(-1, 1, length.out = K) res <- map( 1:I, \(seed) sim_f(N, K, seed), .progress = TRUE ) |> list_rbind() |> pivot_longer(!term) |> mutate(value = replace_na(value, 0)) res |> ggplot(aes(x = term, y = value, fill = name)) + geom_violin() + geom_boxplot(fill="white", width = 0.2) + geom_hline(yintercept = beta, linetype = 2, color = "darkgray") + facet_wrap(vars(name)) + theme(legend.position = 'none') + labs(x = "説明変数", y = "偏回帰係数", title = "素直なデータ", subtitle = "300回試行")
サンプルサイズが少ないケース
今度は説明変数の数が多く、サンプルサイズが少ないケースを考えます。
ただ、サンプルサイズが説明変数の数より小さくなると線形回帰の解が出ないので、サンプルサイズを説明変数の数+1にしています。
説明変数101個、サンプルサイズ102個です。
真の偏回帰係数がそれぞれ-1, -0.5, 0, 0.5, 1である説明変数について推定値を確認します。
線形回帰は真の値を中心に分布していますがとにかくバラツキが大きいので、個々の分析においては外れている可能性が大きそうです。
Ridgeは推定値が安定していますが、ほとんどゼロに近く過小推定の傾向にあります。
LASSO, エラスティックネットも安定しているがやや過小評価の傾向が見られます。
適応的LASSOが比較的ましですがやはり若干過小評価の傾向にはあります。

K <- 101 N <- 102 I <- 300 beta <- seq(-1, 1, length.out = K) res <- map( 1:I, \(seed) sim_f(N, K, seed), .progress = TRUE ) |> list_rbind() |> pivot_longer(!term) |> mutate(value = replace_na(value, 0)) res |> dplyr::filter(term %in% c("V1", "V26", "V51", "V76", "V101")) |> mutate(term = factor(term, levels=c("V1", "V26", "V51", "V76", "V101"))) |> ggplot(aes(x = term, y = value, fill = name)) + geom_violin() + geom_boxplot(fill="white", width = 0.2) + geom_hline(yintercept = c(-1, -0.5, 0, 0.5, 1.0), linetype = 2, color = "darkgray") + facet_wrap(vars(name)) + theme(legend.position = 'none') + coord_cartesian(ylim = c(-2,2))+ labs(x = "説明変数", y = "偏回帰係数", title = "サンプルサイズが少ないデータ", subtitle = "300回試行")
といったところで、正則化項付き線形回帰は予測モデルとしては使えても、それぞれの偏回帰係数を影響力の大きさとして解釈するのはやはり難しそうですね。
参考文献はこちら。
")
モダンチョキチョキズ全アルバムレビュー
令和版モダチョキ(モダンチョキチョキズ)の東京初ライブにうっかり参加してしまってから、モダチョキ熱が冷めない。
それで30年ぶりぐらいにアルバムを聴きなおしているだけど、当時は気付かなかったいろいろな発見があって面白い。
なので熱に浮かされた状態でアルバムレビュー(というほどでもないメモ)でも書いてみる。
『ローリング・ドドイツ』

1992年7月22日リリース。
収録曲は以下。
衝撃のデビュー作といったところ。
前半はTheモダチョキと言えるキラーチューンの雪崩打ち。
「恋の山手線」「新・オバケのQ太郎」「愚か者」はカバーなんだけど、原曲に敬意を表しつつも完全に「これがモダチョキだ!」という音楽となっているのが素晴らしい。
Señor Coconut*1やNouvelle Vague *2の仕事と比べても全く遜色がない。
令和版モダチョキのライブでも盛り上がりましたね。
そして特筆すべきは、ちょいちょい挟まれるフィリップ君のダジャレの切れ味の鋭さ。
これは本当にモダチョキでしか体験できない。
一方でアルバムとしてのまとまりには欠ける。これは1stアルバムなのでまあ仕方のないところ。
あと、ヌルピョンの魅力は音だけでは伝わらないなー、というのとモダチョキの重要なコンポーザーである長谷部信子さんの楽曲が含まれていないのが今となっては物足りないところです。
『ボンゲンガンバンガラビンゲンの伝説』

1993年6月21日リリース。
収録曲は以下。
まあ、名盤っす。
きゃりーぱみゅぱみゅも幼少のみぎりに愛聴していたそうな。
複数の作曲者がいて局長も多彩で、カバー曲も多く含むのに、アルバムとしての構成がすばらしい。
そのうえで長谷部信子さん作曲の名曲群「海の住人」「ふられ節」「凍りの梨」、保山ひゃんの歌詞(替え歌)が冴える「有馬ポルカ」、そしてそしてモダチョキでしか成立しえない「アルサロ・ピンサロ」「博多の女」、なんなんだ「蛇はスネーク」、最後を締める「博多の女」と個々の楽曲の完成度が高い。
そして、ここが大事なんだけど、笑いの要素が違和感なく差し込まれてる。それがアルバムとしての完成度を高めてる。
改めて評価されて欲しい1枚です。
『別冊モダチョキ臨時増刊号』

1994年6月22日リリース。
収録曲は以下。
さて、ここからが問題なのです。
これはここまでに出たシングルに未発表曲とリミックス、コントを加えた編集盤です。
おそらくタイアップの付いたシングルがそこそこ売れて、タイミング的にまとめて出しておきたかったのでしょう。
「ジャングル日和」はCMに使われたのでモダチョキは知らなくてもこの曲は印象に残っている人も多いでしょう。
「自転車に乗って、」と「天体観測」は長谷部信子さん作曲の名曲。モダチョキのポップサイドの代表曲と言っていいでしょう。
「天体観測」は編曲がフェアチャイルドの戸田誠司さんで軽快なテクノポップ調の仕上がり。
未発表曲の方にも「素敵な空気」という佳曲があります。一聴して「遊佐未森っぽい?」と感じましたが編曲の中原信雄さんが遊佐未森さんのスタッフでもあるのですね。なるほど。
しかしながら、全体としてはまったくまとまりがなく、一つの作品として聴くのはちょっとツラい。
YMOの『サービス』みたいな構成なんだけど、途中に挟まれるコントが厳しい。フィリップ君の使い方を間違えてるよ……
ちなみにSpecial Thanksの欄に真城めぐみさんの名前があります。このころからかかわってらっしゃったんですね。
『くまちゃん』

1994年11月2日リリース。
収録曲は以下。
3rdアルバムにして現段階ではラストアルバム。
迷走感が否めない。端的に言ってモダチョキっぽくない。なんかキレイなJ-Popにまとめようとして失敗してる。
「エケセテネ」とか「I wish...」とかいい曲もあるのだが、モダチョキが得意なはずのカバー曲もなんか違う感じ。
なお、「I wish...」は濱田マリさんと真城めぐみさんのデュエットとのこと。
おそらくこのアルバムの制作中にフィリップ君や長谷部信子さんが脱退している。まあ、いろいろあったのであろう。
『レディメイドのモダン・チョキチョキズ』

1997年2月21日リリース。
収録曲は以下。
DISK 1
- B.M.W. (Black Magic Woman)
- ハロー!ドドイツ
- エケセテネ KONISHI'S EDIT
- 自転車に乗って、 (remixed by KONISHI yasuharu)
- トムのいる木蔭
- らいか いのしし
- チープジョーク イン ジャパン
- ピ ピカソ (MODER-CHOKIES MIX)
- 新・オバケのQ太郎 (MEGA MIX)
- 主婦になったバーゲン娘 (ガンポンギーのテーマ)
- 愚か者
- 土曜の夜何かが起きる(黛ジュンのカバー)
- 博多の女
- アルサロ ピンサロ (パヤツのテーマ)
- 天国への段階
- くまちゃん
- あの世へ帰りたい
DISK 2(8cmCD/ボーナストラック野郎)
さて、これが大問題。
おそらくはモダチョキの活動が難しくなって、契約消化のために出されたベスト盤。
タイトルから分かる通り、小西康陽が選曲、編集、リミックスを担当。
分かりやすいのが「自転車に乗って、 (remixed by KONISHI yasuharu)」で、これピチカート・ファイヴ「ベイビィ・ポータブル・ロック」とのマッシュアップです。
「ピピカソ」ってなんか水曜日のカンパネラの「エジソン」っぽいよね。
これだけだと、あえて入手するほどではないんですが、問題は付属の冊子で、モダチョキの全歌詞が載ってる。さらに主要メンバーのリストも!
ということで資料として手元に置いておきたいです。
はい、以上です。
ライブ楽しかったので、また東京でやって欲しいなぁ!
湿度の変化はどうなっているのか?
前回の記事の補足です。
X(旧Twitter)でこんなコメントをいただきました。
沖縄がキツいのは湿度と日差しの強さなので、そういう比較のグラフも見てみたいけど。夏の気温だけでいうと埼玉や新潟の方が高いのは実感としてある。 https://t.co/1Zg9Q2mzOo
— ◤◢NK Apple User ◤◢ (@n_kuramoto) 2023年8月27日
平均湿度のデータなら前回取得しているのでちょっとグラフにしてみましょう。
ただ、湿度のデータは1960年以降しかありません。
まず、前回のデータを呼び出してざっと整形します。
library(conflicted) library(tidyverse) library(RcppRoll) #移動平均 # 前回保存したデータを呼び出す attach("data_heatmap_tokyo.RData") attach("data_heatmap_sapporo.RData") attach("data_heatmap_naha.RData") attach("data_heatmap_akita.RData") # がっちゃんこ data <- bind_rows( data_heatmap_tokyo, data_heatmap_sapporo, data_heatmap_naha, data_heatmap_akita, .id = "city" ) |> mutate(city = case_when( city==1~"東京", city==2~"札幌", city==3~"那覇", city==4~"秋田" )) |> dplyr::filter(year >= 1960) #湿度のデータは1960年以降しか存在しない
最初に分布を見てみましょう。
data |> dplyr::filter(month == "08") |> ggplot(aes(x = age, y = mean_humidity)) + geom_violin(fill = "orange") + geom_boxplot(width = 0.3, fill = "lightblue", outlier.shape = NA) + theme( text = element_text(size = 9), axis.text.x = element_text(angle = 270, hjust = 1) ) + facet_wrap(vars(city), ncol=2) + labs(title = "8月の平均湿度の分布", x = "年代", y = "平均湿度")

気温の変化のような明確な傾向は見えないですね。
ただ、東京の2010年代以降が上昇傾向にあるのがちょっと気になります。
今度はヒートマップを書いてみましょう。
ヒートマップ用関数。
humidity_heatmap <- function(df, title) { df |> drop_na(mean_humidity) |> ggplot(aes(x = day, y = year, fill = mean_humidity)) + geom_tile(color="black") + scale_y_reverse() + facet_grid(. ~ month) + theme( axis.text.x = element_text(angle = 90, hjust = 1, size = 3) ) + scale_fill_gradientn(colors = c("blue", "yellowgreen", "yellow","red")) + labs(title = title, x = "日", y = "年", fill = title) }
東京:
data |> dplyr::filter(city == "東京") |> humidity_heatmap("東京の平均湿度")

むむむ、やはり2015年あたりから湿度が上昇している様子があります。
実は東京の気象観測地点が2014年に東京・大手町の気象庁本庁舎から北の丸公園(千代田区)に移動しており、その影響ではないかと思われます。
札幌:
data |> dplyr::filter(city == "札幌") |> humidity_heatmap("札幌の平均湿度")

秋田:
data |> dplyr::filter(city == "秋田") |> humidity_heatmap("秋田の平均湿度")

那覇:
data |> dplyr::filter(city == "那覇") |> humidity_heatmap("那覇の平均湿度")

那覇は6月の湿度が高いんですね。梅雨の影響でしょうか。
まとめて:
data |> drop_na(mean_humidity) |> ggplot(aes(x = day, y = year, fill = mean_humidity)) + geom_tile() + scale_y_reverse() + facet_grid(city ~ month) + theme( axis.text.x = element_text(angle = 270, hjust = 1, size = 3) ) + scale_fill_gradientn(colors = c("blue", "yellowgreen", "yellow","red")) + labs(title = "平均湿度", x = "日", y = "年", fill = "平均湿度")

こうしてみると、この60年間で特に湿度が上がっている様子はないようです。
偏差のグラフも描いてみましょう。
まず、偏差グラフの関数を作ります。
my_plot <- function(df) { reference_value <- df |> dplyr::filter(year >= 1991, year <= 2020) |> summarise(mean_mean = mean(mean_humidity, na.rm = TRUE)) df |> summarise( mean_humidity = mean_humidity |> mean(na.rm = TRUE), .by = year ) |> mutate( year = year, diff_mean = mean_humidity - reference_value$mean_mean, `平均湿度の移動平均` = roll_mean(diff_mean, n = 5, align = "right", fill = NA, na.rm = TRUE), .keep = "none" ) |> select(year, `平均湿度の移動平均`) |> pivot_longer(!year) |> ggplot(aes(x = year, y = value)) + geom_hline(yintercept = 0, color = "black", linetype = 2) + geom_line(linewidth = 0.5) + geom_smooth(se = FALSE, linewidth = 1) + coord_cartesian(ylim = c(-5, 10)) + theme(legend.position = "bottom") + labs( subtitle = "偏差の5年移動平均値と平滑曲線", x = "年", y = "湿度の偏差" ) }
東京:
data |> dplyr::filter(city == "東京", month == "08") |> my_plot() + labs(title = "東京(8月)")

直近10年ほどで急上昇していますが、これは前述した観測地点の移動によるものと思われます。
札幌:
data |> dplyr::filter(city == "札幌", month == "08") |> my_plot() + labs(title = "札幌(8月)")

秋田:
data |> dplyr::filter(city == "秋田") |> my_plot() + labs(title = "秋田(8月)")

札幌と秋田はむしろ湿度が下がってきてますね。
那覇:
data |> dplyr::filter(city == "那覇") |> my_plot() + labs(title = "那覇(8月)")

那覇は2005年ぐらいから上昇してますね。これは何なんだろうか?
とはいえ、1960年代の水準に戻ったという程度です。
以上、湿度の変化を見てきましたが、気温ほど激しい変化はないようです。
「昔はこんなに暑くなかった」をR言語で可視化する
2023年の8月もそろそろ終わります。
しかし、まだまだ暑くて秋の気配はまだまだ来ないようです。
さてここ数年、7月に入ったころから「昔はこんなに暑くなかった」「いや、そんなことはない」といった話題がSNSをにぎわせています。
私も数年前にこんなグラフを作って、周りではそこそこ評判良かったです。
東京の8月の最低気温の分布の推移。いまさらだけど、ちゃんと書き直したのもあげておく。最低気温の上限が90年代以降上昇しているという結論は変わらないけど。boxplotもおまけで付けておいた。 pic.twitter.com/wfxgfr7I3O
— ボブさん (@bob3bob3) 2018年7月18日
今年もいろんな人が気温の可視化をしていて、非常に興味深かったです。
いくつか挙げてみましょう。
1) 東京における夏(6月~9月)の気温、過去148年分のヒートマップ。
東京における夏の気温を過去148年分ヒートマップで表現。
— 荻原 和樹@『データ思考入門』講談社現代新書 (@kaz_ogiwara) 2023年7月16日
夏の気温は戦後徐々に上昇傾向にあり、現在では厳しい暑さが7月から9月中旬まで続くことがわかります。
データは気象庁「過去の気象データ検索」から取得。 pic.twitter.com/AdIm92rLKD
これは数年前に評判になった記事のアップデート版ですね。
toyokeizai.net
2) 猛暑日の日数のカウント。
www.facebook.com
これはNHKの関東ローカル番組首都圏ネットワークで紹介されていたグラフですがシンプルでいて非常に分かりやすいです。
3) 基準値との偏差のグラフ
www.data.jma.go.jp
こちらは本家本元気象庁謹製のグラフ。強いです。
松本健太郎さんもこれをベースに独自のグラフを描いています。
comemo.nikkei.com
さて、どの可視化も素晴らしいですが、やっぱり自分で可視化してみたいよね、ということでこれらのグラフをR言語で再現してみます。
方針として、完コピではなくR言語らしい(ggplot2らしい)可視化を目指します。
0) 気温のデータを取得する。
可視化をする前に、大元となるデータを取得しなくてはいけません。
過去の気温のデータは気象庁が公開してくれているので、ありがたくスクレイピングさせてもらいます。
WebAPIで取得できれば良かったんですが、天気予報のWebAPIは見つけられたものの、過去データのものは発見できなくてスクレイピングすることにしました、
まずは使いたいパッケージを一通り呼び出す。
インストールされていなければ自動的にインストールされます。
#パッケージ管理用パッケージ if (!require(pacman)) {install.packages("pacman")} #必要なパッケージがインストールされていなければインストールする pacman::p_load( conflicted, #関数の衝突防止 tidyverse, #モダンなデータ操作 rvest, #Webスクレイピング polite, #紳士的なWebスクレイピング janitor, #データクリーニング RcppRoll, #移動平均算出 ggridges #リッジグラフ )
気象庁の過去の気温のページは地域ごと月ごとに分かれているので、それらを連続して取得し、さらに分析しやすい形に整形まで行う関数を作ります。
# スクレイピングから基本的なクリーニング、データ整形まで一連の流れを関数化 get_temp_data <- function(URL) { URL |> bow() |> # Introduce yourself to the host scrape(content = "text/html; charset=UTF-8") |> # 実際にhtmlファイルを取得 html_table() |> # htmlのテーブルをdf形式に変換 pluck(6) |> # 6個目のテーブルを抜き出す clean_names() |> # 列名を扱いやすい形に整える select(ri, qi_wen_c, qi_wen_c_2, qi_wen_c_3, shi_du) |> # 日付、平均気温、最高気温、最低気温、平均湿度 slice(-(1:3)) |> # 余計な行を取り除く mutate( # 型の変換 day = ri, mean_temp = qi_wen_c |> as.double(), max_temp = qi_wen_c_2 |> as.double(), min_temp = qi_wen_c_3 |> as.double(), mean_humidity = shi_du |> as.integer(), DI = 0.81 * mean_temp + 0.01 * mean_humidity * (0.99 * mean_temp - 14.3) + 46.3, #不快指数 .keep = "none" ) } # 複数年分のデータを一括取得し整形する関数 # base_urlにはhttpsからyear=までのurlを与える。 # year_rangeには取得対象の西暦をベクトルで与える。 # month_rangeには取得対象月をベクトルで与える。 get_multiple_years_data <- function(base_url, year_range, month_range) { year_month_range <- crossing(year_range, month_range) paste0(base_url, year_month_range$year_range, "&month=", year_month_range$month_range, "&day=&view=p1") |> map(\(url) get_temp_data(url), .progress = TRUE) |> list_rbind(names_to = "rowid") |> # 年ごとに分かれたデータを一つにまとめる left_join( # 年を列を追加 year_month_range |> rowid_to_column(), by = join_by(rowid) ) |> select(!rowid) |> # 不要になった列を削除 mutate(age = paste0(floor(year_range / 10) * 10, "s")) |> #年代を追加 rename(year = year_range, month =month_range) #列名の調整 }
これで準備できたので実際にデータを取得します。
今回は、札幌、秋田、東京、那覇の4地点の6月から9月までの気温などデータを取得してみます。
サーバーに負荷がかからないように時間をかけてデータ取得するため、1地点あたり2時間程度かかります。
念のため、データが取得できたらすぐに保存します。
東京:
#1875年から2022年まで data_heatmap_tokyo1 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=44&block_no=47662&year=", year_range = 1875:2022, month_range = 6:9 ) # 今年の8月まで data_heatmap_tokyo2 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=44&block_no=47662&year=", year_range = 2023, month_range = 6:8 ) # がっちゃんこ data_heatmap_tokyo <- bind_rows( data_heatmap_tokyo1, data_heatmap_tokyo2 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) save(data_heatmap_tokyo, file = "data_heatmap_tokyo.RData")
札幌:
data_heatmap_sapporo1 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=14&block_no=47412&year=", year_range = 1879:2022, month_range = 6:9 ) data_heatmap_sapporo2 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=14&block_no=47412&year=", year_range = 2023, month_range = 6:8 ) # がっちゃんこ data_heatmap_sapporo <- bind_rows( data_heatmap_sapporo1, data_heatmap_sapporo2 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) save(data_heatmap_sapporo, file = "data_heatmap_sapporo.RData")
那覇:
data_heatmap_naha1 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=91&block_no=47936&year=", year_range = 1890:2022, month_range = 6:9 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) data_heatmap_naha2 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=91&block_no=47936&year=", year_range = 2023, month_range = 6:8 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) data_heatmap_naha <- bind_rows( data_heatmap_naha1, data_heatmap_naha2 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) save(data_heatmap_naha, file = "data_heatmap_naha.RData")
秋田:
data_heatmap_akita1 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=32&block_no=47582&year=", year_range = 1883:2022, month_range = 6:9 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) data_heatmap_akita2 <- get_multiple_years_data( base_url = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=32&block_no=47582&year=", year_range = 2023, month_range = 6:8 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) data_heatmap_akita <- bind_rows( data_heatmap_akita1, data_heatmap_akita2 ) |> mutate( year, month = formatC(month, width = 2, flag = "0"), day = formatC(as.integer(day), width = 2, flag = "0") ) save(data_heatmap_akita, file = "data_heatmap_akita.RData")
これでデータ取得完了です。
1) 猛暑日の日数
まずは地点ごとに猛暑日の日数をカウントしてみましょう。
# 保存したデータを呼び出す attach("data_heatmap_tokyo.RData") attach("data_heatmap_sapporo.RData") attach("data_heatmap_naha.RData") attach("data_heatmap_akita.RData") # 猛暑日(最高気温35度以上)の日数を年ごとにカウントし棒グラフにする bind_rows( data_heatmap_tokyo |> mutate(city = "東京"), data_heatmap_sapporo |> mutate(city = "札幌"), data_heatmap_naha |> mutate(city = "那覇"), data_heatmap_akita |> mutate(city = "秋田") ) |> mutate( extremely_hot_day = if_else(max_temp >= 35, 1, 0), city = city |> ordered(levels = c("東京", "札幌", "那覇", "秋田")) ) |> select(year, extremely_hot_day, city) |> summarise(extremely_hot_day = sum(extremely_hot_day, na.rm = TRUE), .by = c("year", "city")) |> ggplot(aes(x=year, y=extremely_hot_day, fill = extremely_hot_day)) + geom_col() + scale_fill_gradientn(colors = c("blue", "red")) + labs( title = "6月から9月の猛暑日(最高気温35度以上)の日数", subtitle = "2023年は8月20日までのデータ", x = "年", y = "猛暑日の日数", fill = "日数" ) + facet_wrap(vars(city), ncol=2) + theme( axis.text.x = element_text(angle = 270, hjust = 1) )
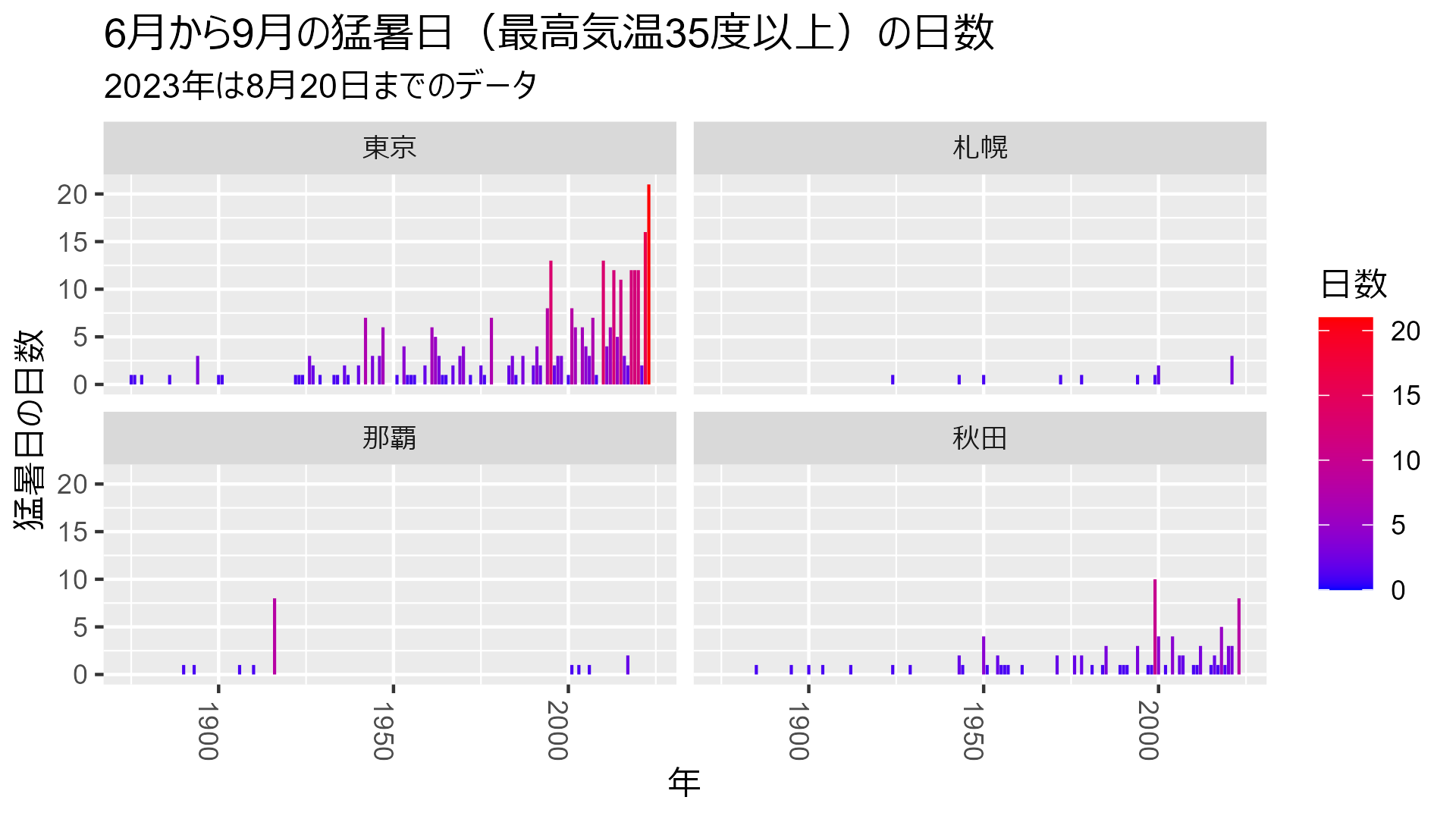
うおお、いきなり東京の増え方がヤバいですね。
秋田も北国のイメージですが意外と多い。
札幌と那覇が似たようなもの。
もしかして沖縄は避暑地になるのか???
せっかくなので真夏日(最高気温30度以上)も含めてカウントしてみましょう。
bind_rows( data_heatmap_tokyo |> mutate(city = "東京"), data_heatmap_sapporo |> mutate(city = "札幌"), data_heatmap_naha |> mutate(city = "那覇"), data_heatmap_akita |> mutate(city = "秋田") ) |> mutate( hot_day = if_else(max_temp >= 30, 1, 0), city = city |> ordered(levels = c("東京", "札幌", "那覇", "秋田")) ) |> select(year, hot_day, city) |> summarise(hot_day = sum(hot_day, na.rm = TRUE), .by = c("year", "city")) |> ggplot(aes(x=year, y=hot_day, fill = hot_day)) + geom_col() + scale_fill_gradientn(colors = c("blue", "red")) + labs( title = "6月から9月の真夏日と猛暑日(最高気温30度以上)の日数", subtitle = "2023年は8月20日までのデータ", x = "年", y = "猛暑日の日数", fill = "日数" ) + facet_wrap(vars(city), ncol=2) + theme( axis.text.x = element_text(angle = 270, hjust = 1) )
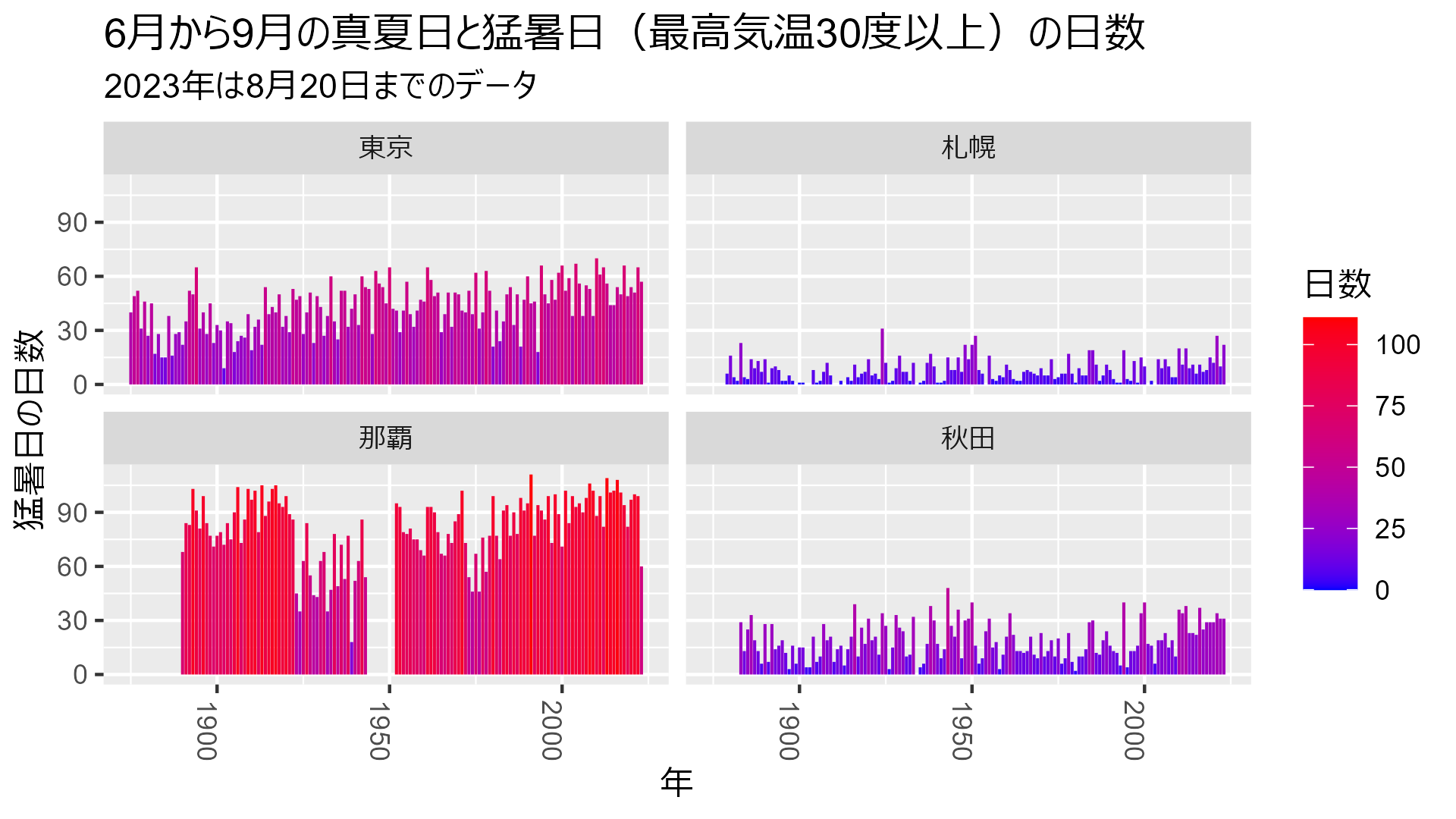
あ、やっぱり全体としては沖縄の方が暑いですね……
2) 平均気温のヒートマップ
お次は平均気温のヒートマップです。
これもいちいち長いコードを書かないで済むように一時的な描画用関数を作ります。
本当は関数内で最高気温の変数名を指定したかったんだけど、うまくできなかったのでtempで決め打ちしてます。
# ヒートマップ描画関数 temp_heatmap <- function(df, title) { df |> drop_na(temp) |> ggplot(aes(x = day, y = year, fill = temp)) + geom_tile(color="black") + scale_y_reverse() + facet_grid(. ~ month) + theme( axis.text.x = element_text(angle = 90, hjust = 1, size = 3) ) + scale_fill_gradientn(colors = c("blue", "yellowgreen", "yellow","red")) + labs(title = title, x = "日", y = "年", fill = title) }
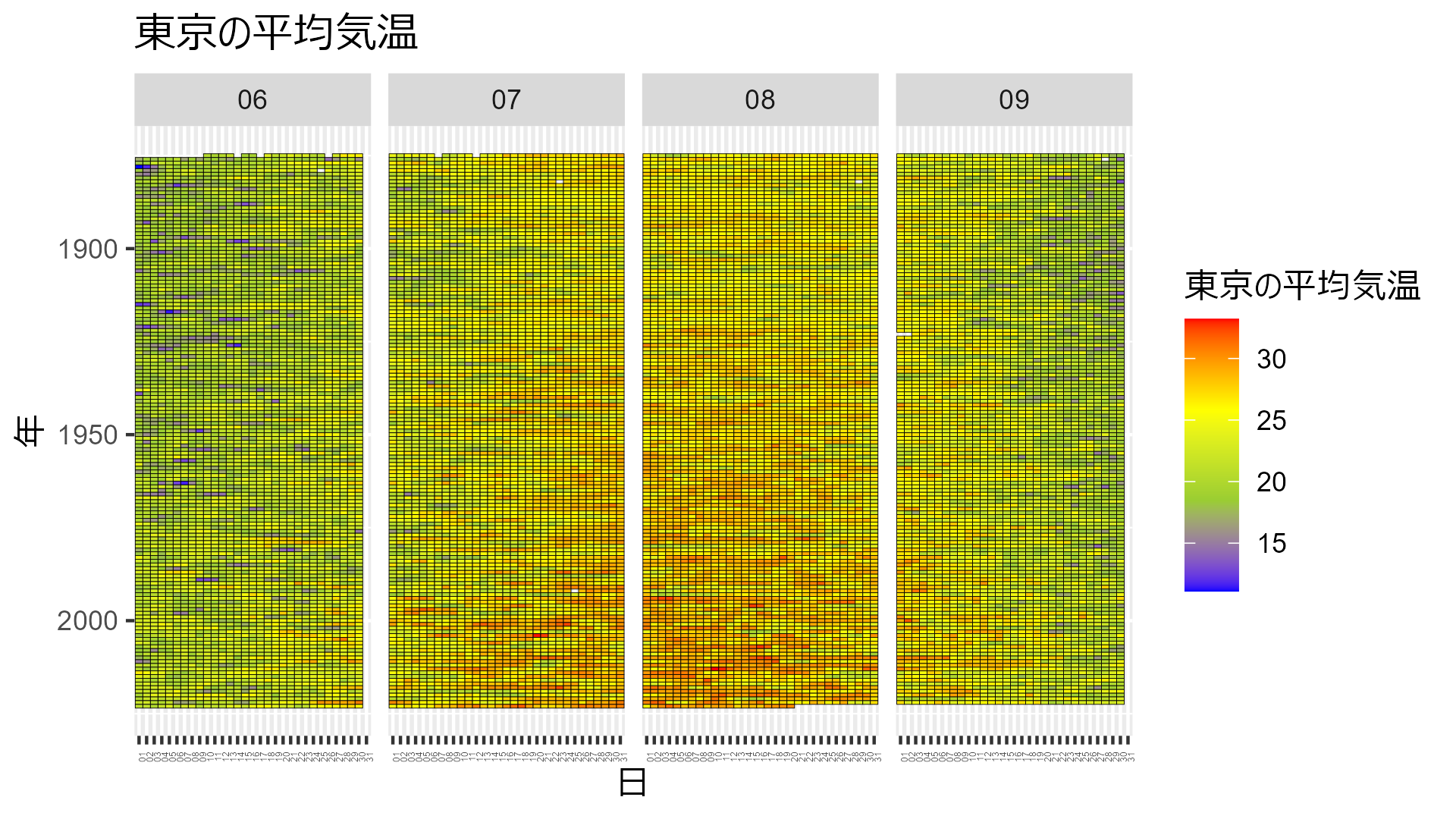
東京:
data_heatmap_tokyo |> mutate(temp = mean_temp) |> temp_heatmap("東京の平均気温")
札幌:
data_heatmap_sapporo |> mutate(temp = mean_temp) |> temp_heatmap("札幌の平均気温")
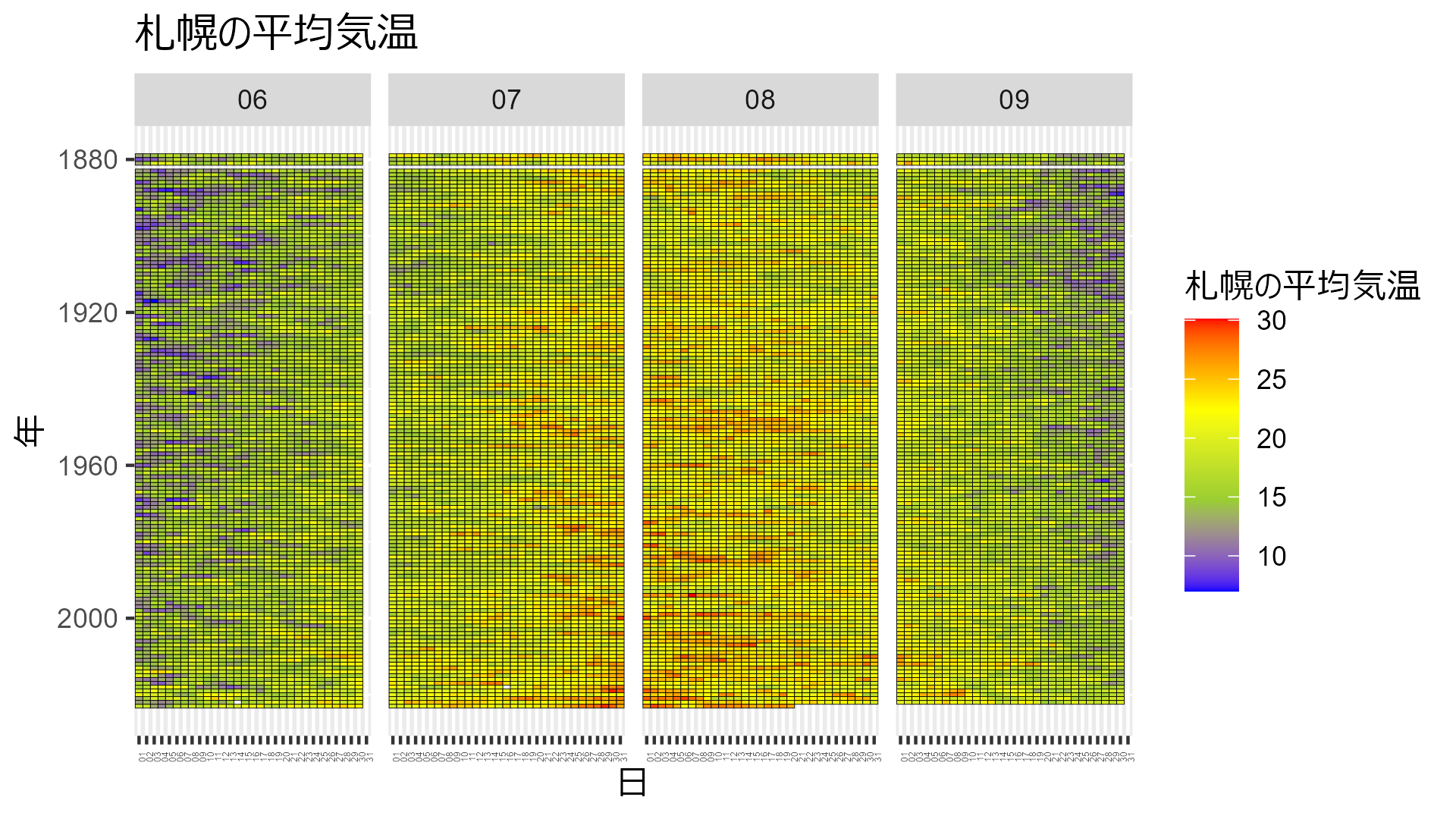
秋田:
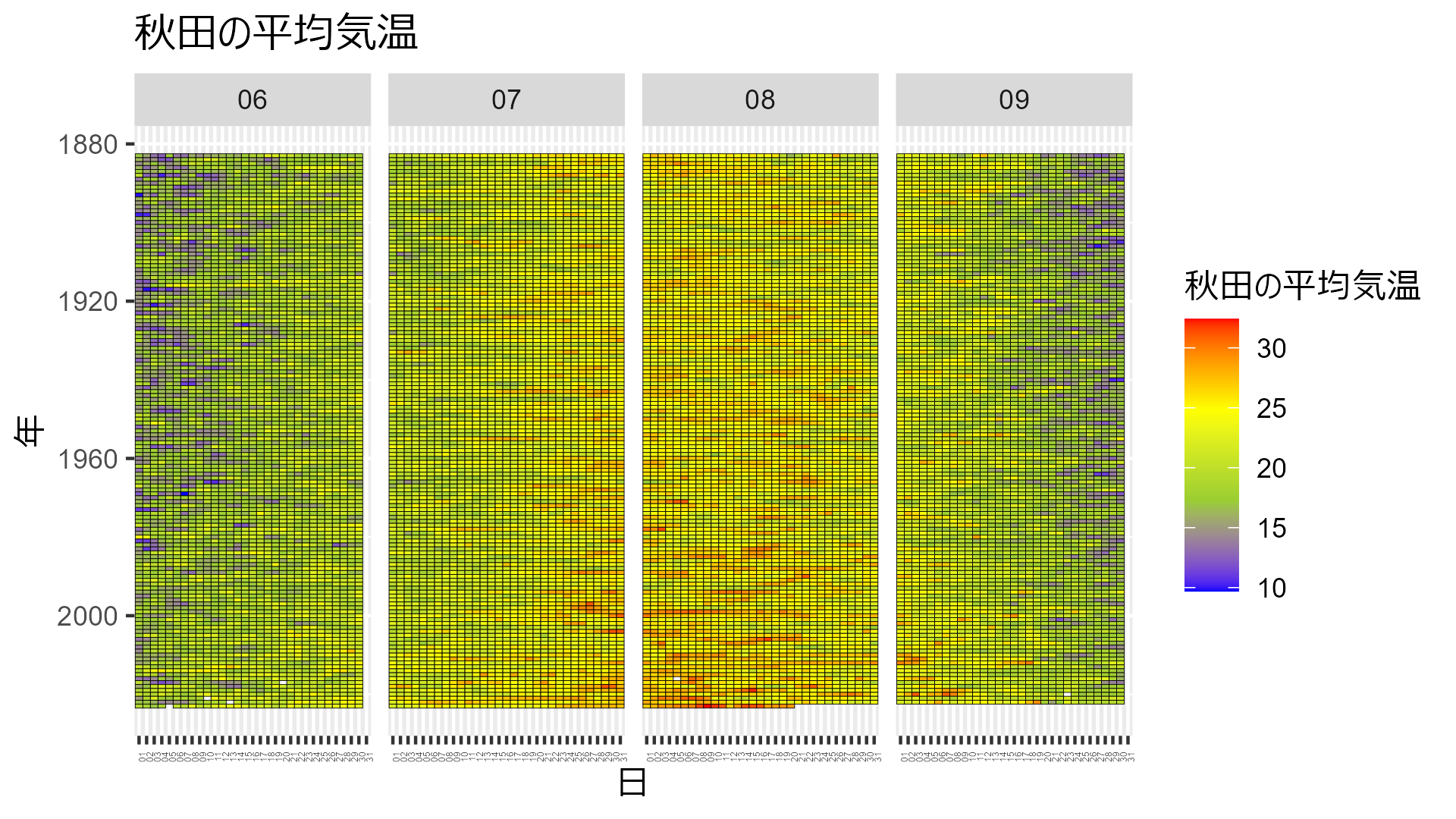
data_heatmap_akita |> mutate(temp = mean_temp) |> temp_heatmap("秋田の平均気温")
那覇:
data_heatmap_naha |> mutate(temp = mean_temp) |> temp_heatmap("那覇の平均気温")
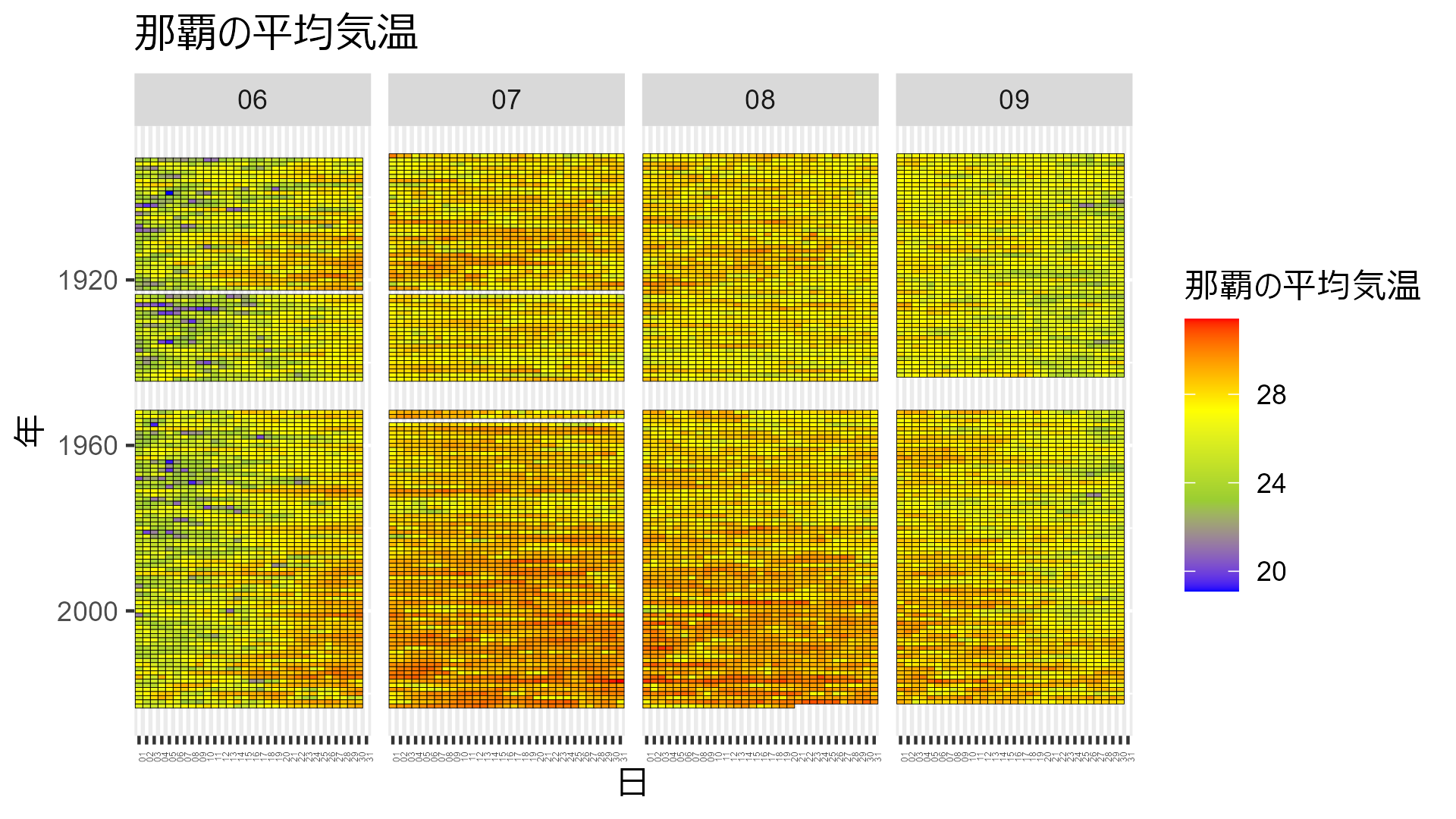
那覇は戦争の期間のデータが欠測値になってますね……
全部まとめちゃいましょう。
data_all <- bind_rows( 東京 = data_heatmap_tokyo, 札幌 = data_heatmap_sapporo, 那覇 = data_heatmap_naha, 秋田 = data_heatmap_akita, .id = "city" ) |> mutate( temp = mean_temp, city = city |> factor(levels = c("札幌", "秋田", "東京", "那覇")) ) data_all |> drop_na(temp) |> ggplot(aes(x = day, y = year, fill = temp)) + geom_tile() + scale_y_reverse() + facet_grid(city ~ month) + theme( axis.text.x = element_text(angle = 270, hjust = 1, size = 3) ) + scale_fill_gradientn(colors = c("blue", "yellowgreen", "yellow","red")) + labs(title = "平均気温", x = "日", y = "年", fill = "平均気温")
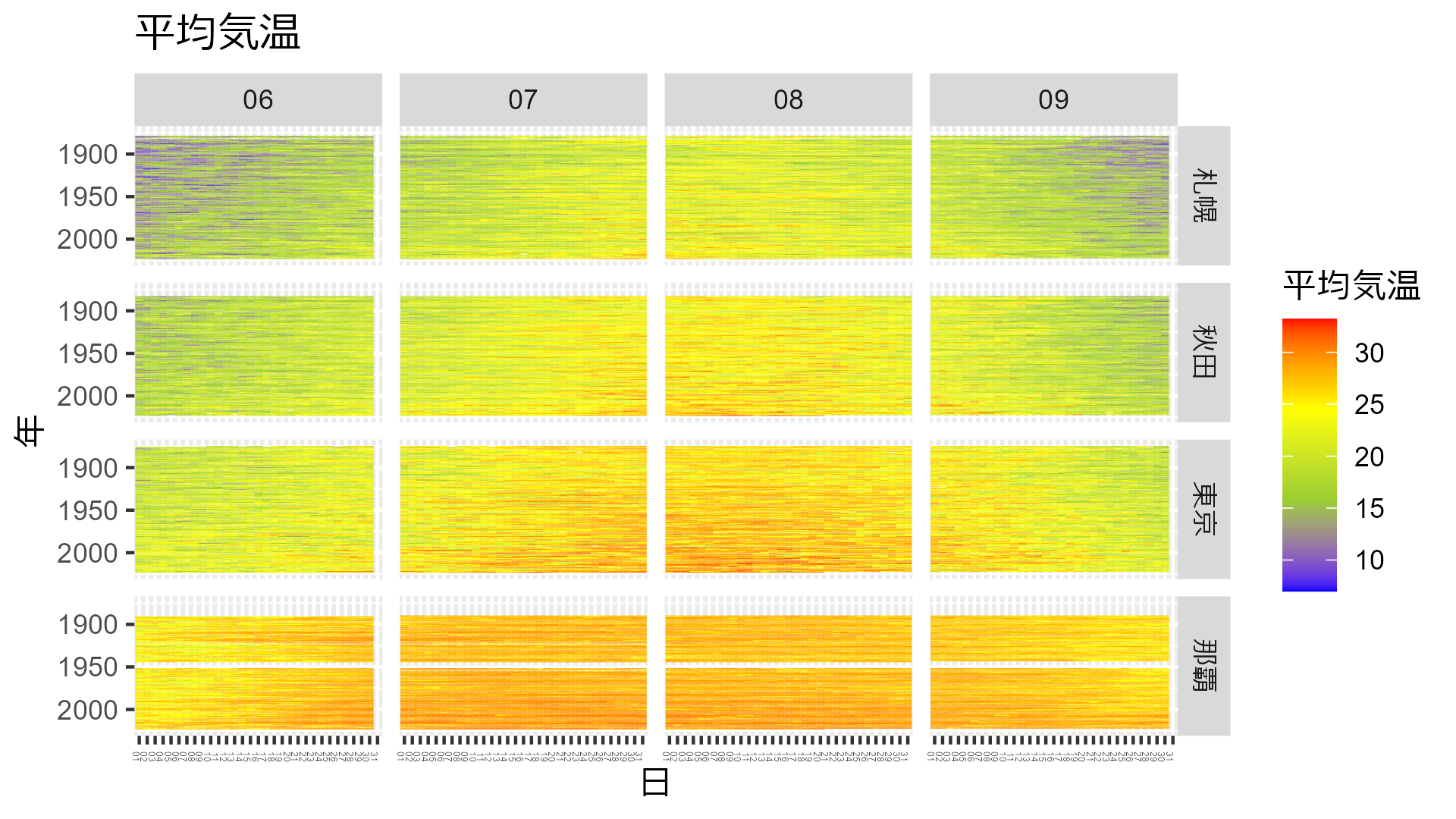
どこも年々気温が高くなり、夏の期間が長くなっていることが分かりますね。
3)偏差のグラフ
気象庁の偏差のグラフは1991年〜2020年の30年平均値を基準値としているので、ここではそれに倣って各地点の基準値との偏差を計算したうえで、5年移動平均値とそれに基づく平滑曲線を描いててみます。
これも地点ごとに簡単に書けるよう一時的な関数を作ります。
my_plot <- function(df) { reference_value <- df |> dplyr::filter(year >= 1991, year <= 2020) |> summarise( mean_max = mean(max_temp, na.rm = TRUE), mean_mean = mean(mean_temp, na.rm = TRUE), mean_min = mean(min_temp, na.rm = TRUE) ) df |> summarise( max_temp = max_temp |> mean(na.rm = TRUE), mean_temp = mean_temp |> mean(na.rm = TRUE), min_temp = min_temp |> mean(na.rm = TRUE), .by = year ) |> mutate( year = year, diff_max = max_temp - reference_value$mean_max, diff_mean = mean_temp - reference_value$mean_mean, diff_min = min_temp - reference_value$mean_min, `最高気温の移動平均` = roll_mean(diff_max, n = 5, align = "right", fill = NA, na.rm = TRUE), `平均気温の移動平均` = roll_mean(diff_mean, n = 5, align = "right", fill = NA, na.rm = TRUE), `最低気温の移動平均` = roll_mean(diff_min, n = 5, align = "right", fill = NA, na.rm = TRUE), .keep = "none" ) |> select(year, `最高気温の移動平均`, `平均気温の移動平均`, `最低気温の移動平均`) |> pivot_longer(!year) |> ggplot(aes(x = year, y = value, color = name, group = name)) + geom_hline(yintercept = 0, color = "black", linetype = 2) + geom_line(linewidth = 0.5) + geom_smooth(se = FALSE, linewidth = 1) + theme(legend.position = "bottom") + labs( subtitle = "偏差の5年移動平均値と平滑曲線", x = "年", y = "気温の偏差", color = "気温の種類" ) }
東京:
data_heatmap_tokyo |> my_plot() + labs(title = "東京")
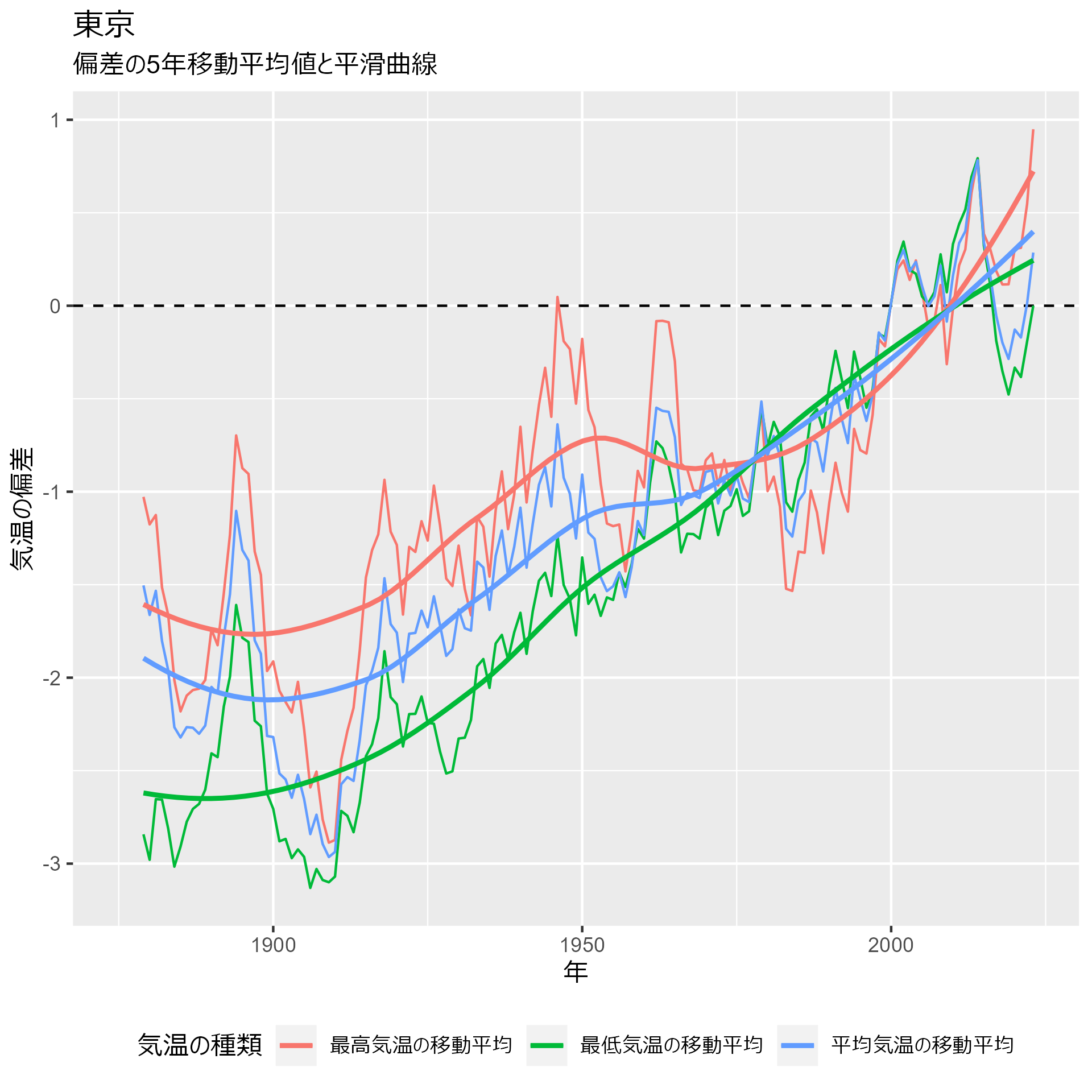
札幌:
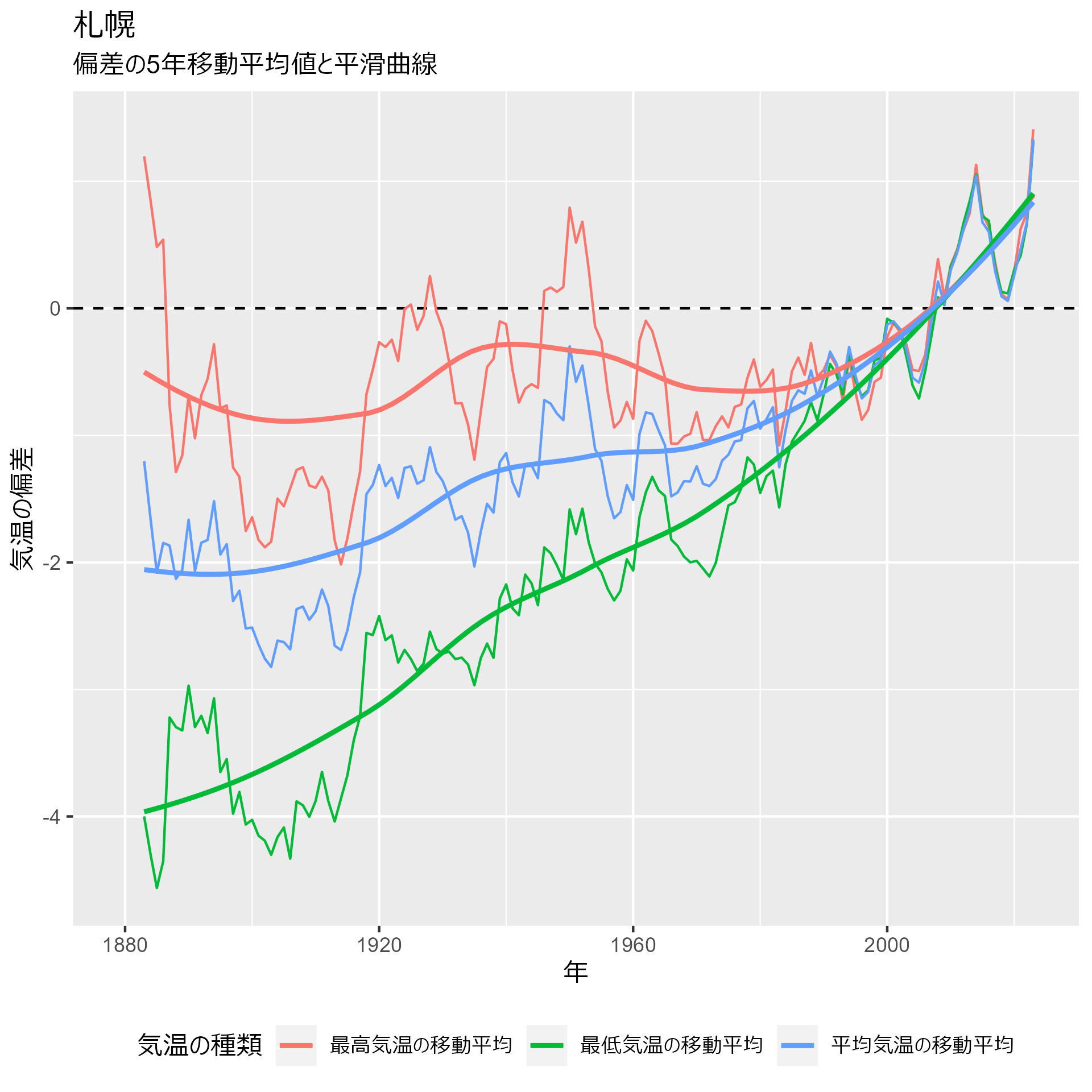
data_heatmap_sapporo |> my_plot() + labs(title = "札幌")
秋田:
data_heatmap_akita |> my_plot() + labs(title = "秋田")
那覇:
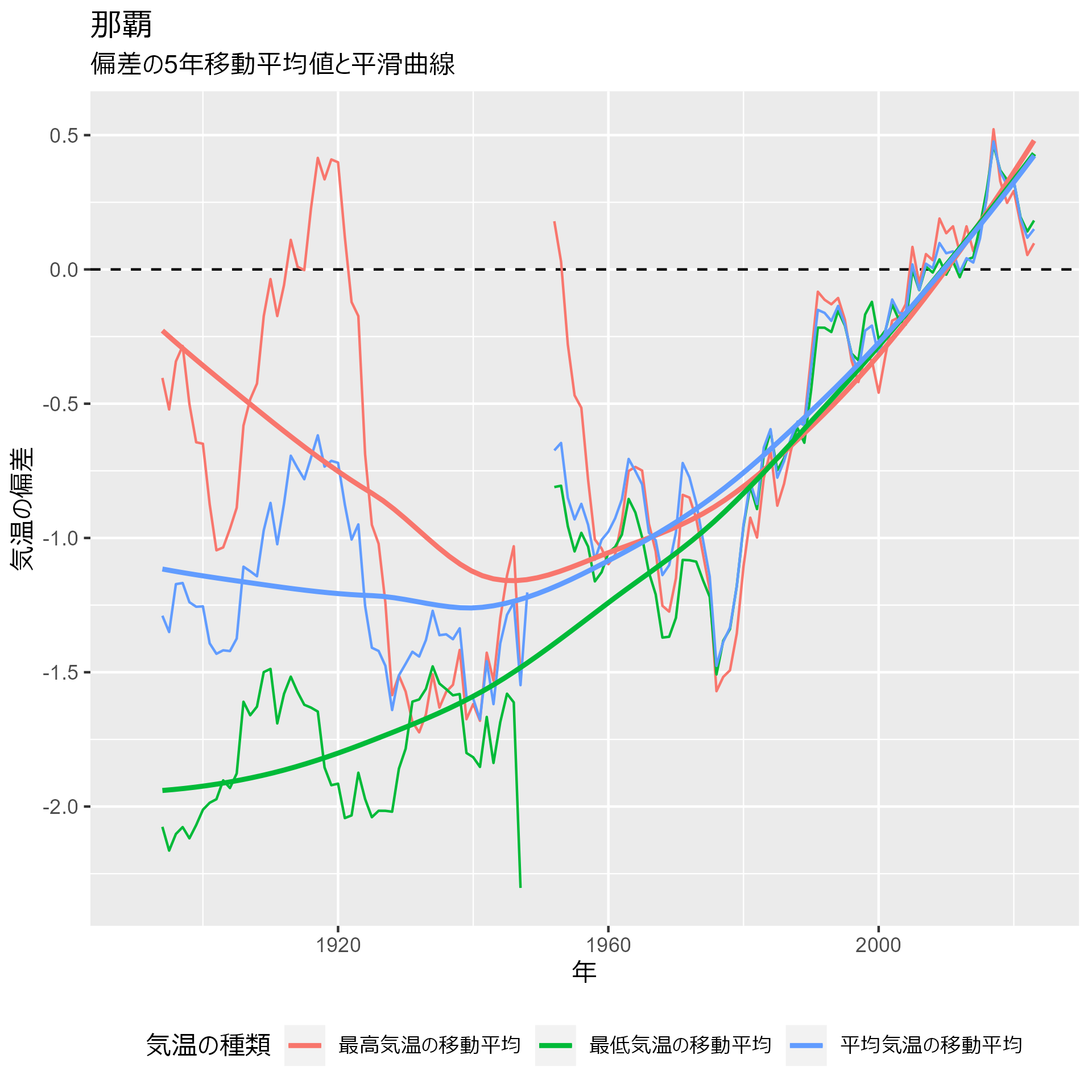
data_heatmap_naha |> my_plot() + labs(title = "那覇")
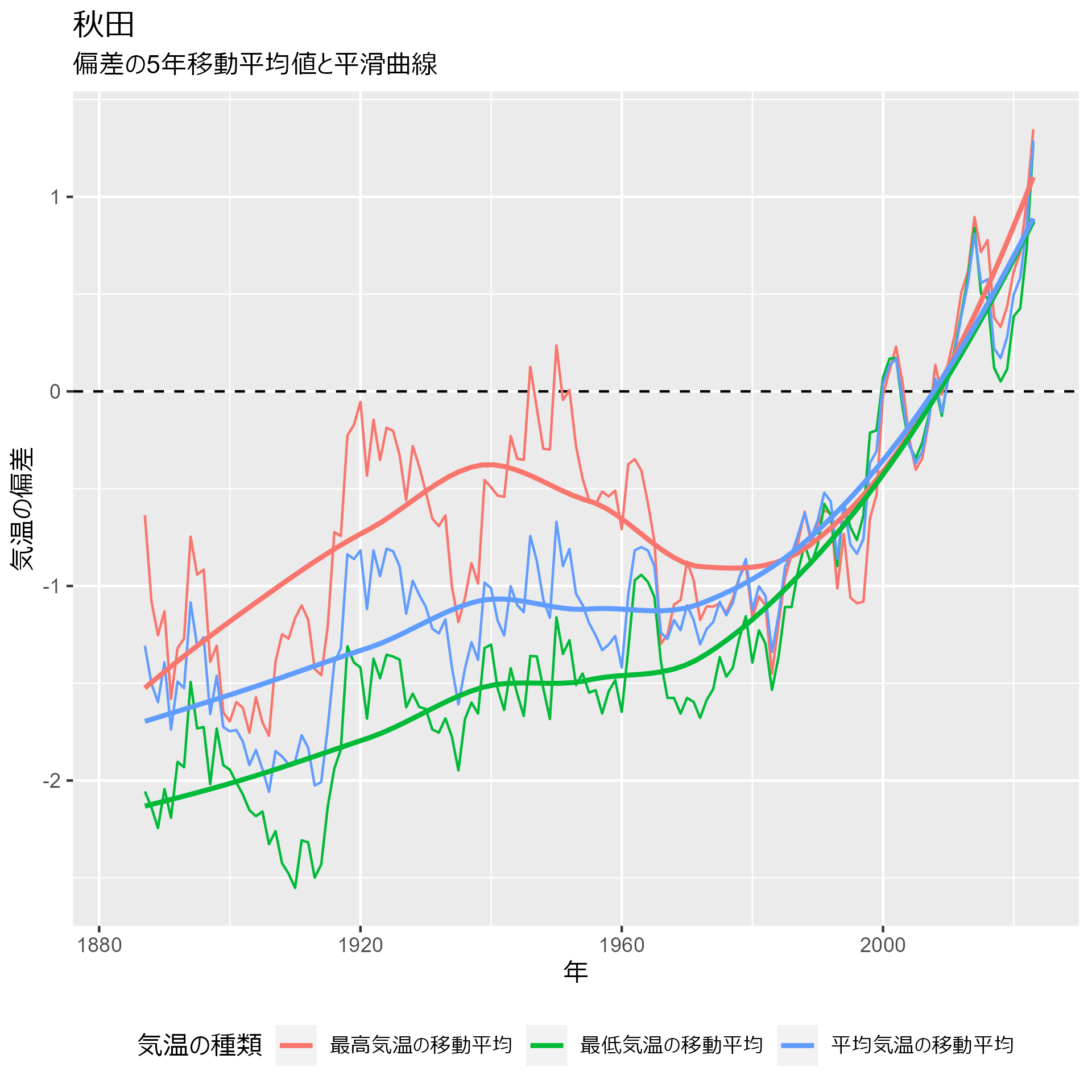
いずれの地点も1980年ごろから動きが変わっていることが分かります。
4)10年ごとの分布で見る
最後にオリジナルな可視化をやってみます。
平均値は分かりやすいのですが、やはり分布の形を見てみたいということで、10年区切りで分布の変化が分かるようなグラフを描いてみます。
ここでは8月の最低気温に絞ってみます。
まず、リッジプロット。
data_all |> dplyr::filter(month == "08") |> ggplot(aes(x = min_temp, y = age, group=age, fill = after_stat(x))) + geom_density_ridges_gradient() + scale_fill_viridis_c(option = "C")+ theme_bw(base_size = 9) + theme(legend.position = "bottom") + scale_x_continuous(limits = c(6, 34)) + facet_wrap(vars(city), ncol=4) + labs(title = "8月の最低気温の分布", x = "最低気温", y = "年代", fill = "最低気温")
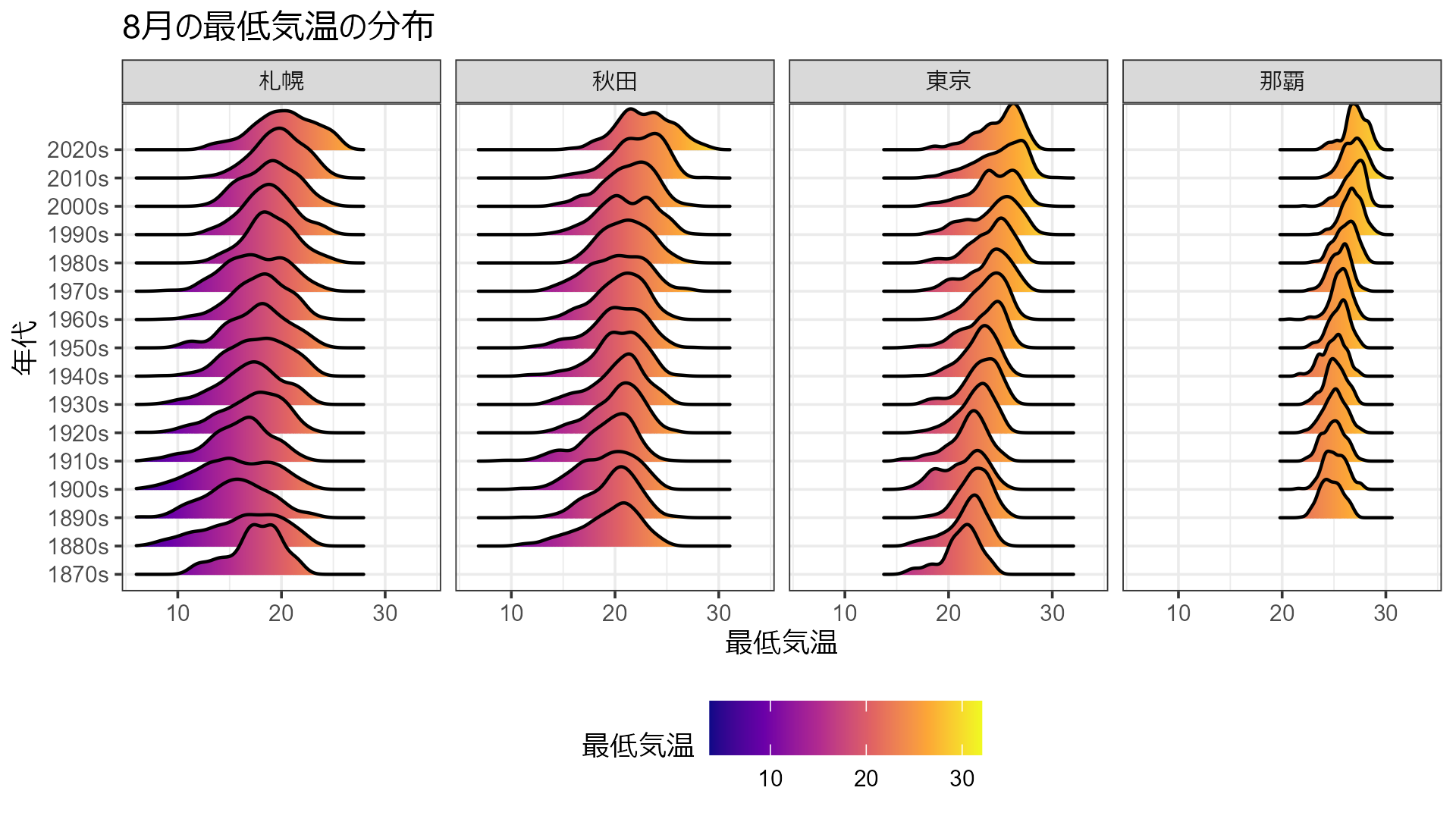
そしてバイオリンプロットと箱ひげ図の組み合わせ。
data_all |> dplyr::filter(month == "08") |> ggplot(aes(x = age, y = min_temp)) + geom_violin(fill = "orange") + geom_boxplot(width = 0.3, fill = "lightblue", outlier.shape = NA) + theme( text = element_text(size = 9), axis.text.x = element_text(angle = 270, hjust = 1) ) + facet_wrap(vars(city), ncol=2) + labs(title = "8月の最低気温の分布", x = "年代", y = "最低気温")

ちょっと詰め込みすぎたかな……
いずれにしても東京の最低気温の上限が年々上がってきているのが分かりますね。
というわけで、Rで色々な可視化を再現してみました。
皆さんもいいグラフを見つけたら自分で再現してみてください。